서론
AtCoder Next DP Contest (link)에 출제된 20문제의 DP 문제 중 앞 14문제의 풀이입니다. solved.ac 기준 실버 상위권부터 다이아 중위권 정도 범위의 문제를 다룹니다.
유형과 solved.ac 기준 체감 난이도는 다음과 같습니다.
| 문제 |
유형 |
난이도 |
| A. Polyomino |
기초 DP |
S2 - G5 |
| B. DAG |
DAG DP |
G3 |
| C. String |
기초 DP |
G5 - G3 |
| D. Banknote |
Digit DP |
P3 |
| E. Summer Vacation |
스파스 테이블 |
D5 |
| F. Set |
카르테시안 트리, 검은돌 |
D4 - D3 |
| G. Mouth |
구간 최대 합 세그먼트 트리 |
D5 |
| H. Coin |
기초 DP, 누적 합 |
G1 - P4 |
| I. Update Positions |
조합론 |
P2 - D5 |
| J. Number and Total |
Digit DP, 배낭 문제 |
D5 - D3 |
| K. Addition and Subtraction |
배낭 문제, 비트셋 |
P1 - D5 |
| L. LCM |
뫼비우스 반전 공식 |
P1 - D5 |
| M. Numeral |
SOS DP |
D5 |
| N. Knapsack |
배낭 문제, 그리디 |
D3 이상 |
A. Polyomino
$2\times 1$ 크기의 블록과 $3$칸짜리 ㄴ 모양의 블록을 이용해 $2\times N$ 크기의 격자를 채우는 경우의 수를 구하는 문제
$1 \le N \le 40$
세로로 쪼갤 수 없는 $2 \times n$ 크기의 덩어리를 만드는 방법의 수를 생각해 봅시다. $n = 1$ 일 때는 $2\times 1$ 크기의 블록을 세로로 배치하는 것 1가지, $n = 2$ 일 때는 $2\times 1$ 크기의 블록 2개를 위 아래로 배치하는 것 1가지가 있습니다.
$n = 3$ 일 때는 ㄴㄱ 모양으로 배치하는 것과 반대로 배치하는 것까지 총 두 가지가 있습니다. $n$이 3 보다 큰 홀수일 때는 ㄴ과 ㄱ 사이에 $2\times 1$ 크기의 블록을 위 아래로 각각 $(n-3)/2$개씩 배치할 수 있으므로, $n$이 3 이상인 홀수라면 항상 두 가지 방법이 존재합니다.
$n = 4$ 일 때는 ㄴ 모양 블록 2개를 아래와 같이 배치한 뒤, 빈 공간에 $2\times 1$ 크기의 블록 1개를 가로로 배치하는 방법과, 이를 상하 반전시킨 것까지 총 두 가지 방법이 존재합니다.
$n$이 4보다 큰 짝수일 때는 두 ㄴ 모양 블록 사이에 $2\times 1$ 크기의 블록을 위 아래로 각각 $(n-4)/2$개씩 배치할 수 있으므로, $n$이 4 이상인 짝수일 때도 항상 두 가지 방법이 존재합니다.
따라서 $D(n) = D(n-1) + D(n-2) + 2\times \sum_{i=3}^n D(n-i)$라는 점화식을 얻을 수 있습니다. $N \le 40$ 이므로 $O(N^2)$에 계산해도 충분합니다.
void Solve(){
cin >> N;
D[0] = D[1] = 1;
for(int i=2; i<=N; i++){
D[i] = D[i-1] + D[i-2];
for(int j=3; j<=i; j++) D[i] += D[i-j] * 2;
}
cout << D[N] << "\n";
}
$S(n) = D(0) + D(1) + \cdots + D(n)$이라고 정의하면 $D(n) = D(n-1) + D(n-2) + 2S(n-3)$으로 계산할 수 있으므로 $O(N)$ 시간에 계산할 수도 있습니다.
상태 전이를 아래와 같이 행렬 곱셈으로 표현할 수 있다는 점을 이용해 $O(\log N)$ 시간에 계산할 수도 있습니다.
\[\begin{pmatrix}1&1&0\\0&0&1\\2&1&1\end{pmatrix}\begin{pmatrix}S(n-3)\\D(n-2)\\D(n-1)\end{pmatrix}=\begin{pmatrix}S(n-2)\\D(n-1)\\D(n)\end{pmatrix}\]
void Solve(){
cin >> N;
matrix A({ {1, 1, 0}, {0, 0, 1}, {2, 1, 1} });
matrix B({ {1}, {1}, {2} }); // {S[0]; D[1]; D[2]}
// A^{N-2} * B = {S[N-2]; D[N-1]; D[N]}
if(N <= 2) cout << N << "\n";
else cout << (Pow(A, N-2) * B)[2][0] << "\n";
}
B. DAG
$N$개의 정점과 $M$개의 간선으로 구성된 DAG에서 $1 \rightarrow N$ 경로 개수를 구하는 문제
$2 \le N \le 2\times 10^5$; $0 \le M \le \min(N(N-1)/2, 2\times 10^5)$; simple DAG
$1$번 정점에서 $v$번 정점으로 가는 경로의 수를 $D(v)$라고 정의합시다. 처음에는 $D(1)$만 $1$인 상태에서 시작합니다.
$x$에서 $y$로 가는 간선이 있다면 $D(x)$를 $D(y)$에 더해야 하는데, $D(x)$의 값이 확정된 후에 이러한 덧셈 연산을 해야 한다는 문제가 있습니다. 연산의 순서를 잘못 처리하는 경우 올바르지 않은 값이 더해질 수 있어서 순서를 잘 정해야 하는데, 이는 위상 정렬 순서대로 처리하면 쉽게 해결할 수 있습니다.
정점을 위상 정렬 순서대로 보면서 경로의 수를 계산합니다. 현재 $x$번 정점을 보고 있고, $x$에서 $y$로 가는 간선이 있다면 $D(x)$를 $D(y)$에 더하면 $O(N+M)$ 시간에 문제를 해결할 수 있습니다.
void Solve(){
cin >> N >> M;
for(int i=1,u,v; i<=M; i++) cin >> u >> v, G[u].push_back(v), In[v]++;
D[1] = 1;
queue<int> Q;
for(int i=1; i<=N; i++) if(!In[i]) Q.push(i);
while(!Q.empty()){
int v = Q.front(); Q.pop();
for(auto i : G[v]){
D[i] += D[v];
if(D[i] >= MOD) D[i] -= MOD;
if(!--In[i]) Q.push(i);
}
}
cout << D[N] << "\n";
}
C. String
문자열 $S_1,S_2,S_3$이 주어지면, 세 문자열을 모두 subsequence로 포함하지 않는 길이가 $N$인 문자열의 수를 구하는 문제
$1 \le N \le 10^3$; $1 \le \vert S_i\vert \le 10$
$S_i$의 첫 $p_i$글자를 subsequence로 포함하는 길이가 $n$인 문자열의 개수를 $D(n,p_1,p_2,p_3)$라고 정의합시다.
현재 상황이 $(n, p_1, p_2, p_3)$인 상황에서 $n+1$번째 문자로 $c$를 붙인다고 하면, $S_i[p_i] = c$ 일 때 $p_i$가 1 증가합니다. 이 관계를 그대로 점화식으로 옮겨서 계산하면 $O(26N\times \prod\vert S_i\vert)$ 시간에 문제를 해결할 수 있습니다.
void Add(int &a, const int b){ if((a += b) >= MOD) a -= MOD; }
void Solve(){
cin >> N;
for(int i=0; i<3; i++) cin >> A[i];
for(int i=0; i<3; i++) S[i] = A[i].size();
D[0][0][0][0] = 1;
for(int i=0; i<N; i++){
for(int x=0; x<S[0]; x++){
for(int y=0; y<S[1]; y++){
for(int z=0; z<S[2]; z++){
const int now = D[i][x][y][z];
if(!now) continue;
for(int c=0; c<26; c++){
int xx = x + (A[0][x]-'a' == c);
int yy = y + (A[1][y]-'a' == c);
int zz = z + (A[2][z]-'a' == c);
Add(D[i+1][xx][yy][zz], D[i][x][y][z]);
}
}
}
}
}
int res = 0;
for(int x=0; x<S[0]; x++) for(int y=0; y<S[1]; y++) for(int z=0; z<S[2]; z++) Add(res, D[N][x][y][z]);
cout << res << "\n";
}
만약 subsequence가 아니라 substring 조건이 있었다면, KMP 알고리즘의 실패 함수를 이용해서 같은 시간에 문제를 해결할 수 있습니다. 구체적으로, $S[0:p] + c$와 일치하는 $S$의 가장 긴 접두사의 길이 $F(p, c)$를 $O(26\times \vert S\vert)$ 시간에 계산하면, 점화식의 상태 전이는 위 코드에서 xx를 구할 때 xx = F[x][c]를 사용하는 식으로 계산할 수 있습니다. 2020년 ICPC 서울 예선 B번 문제에서 연습할 수 있습니다.
vector<int> GetFail(const string &s){
int n = s.size();
vector<int> fail(n);
for(int i=1, j=0; i<n; i++){
while(j > 0 && s[i] != s[j]) j = fail[j-1];
if(s[i] == s[j]) fail[i] = ++j;
}
return fail;
}
void GetNext(const string &s, int nxt[][26]){
int n = s.size();
auto fail = GetFail(s);
for(int i=0; i<n; i++){
for(int c=0; c<26; c++){
int j = i;
while(j > 0 && s[j] != c+'a') j = fail[j-1];
if(s[j] == c+'a') nxt[i][c] = ++j;
}
}
for(int c=0; c<26; c++) nxt[n][c] = n;
}
D. Banknote
$1,10,100,\cdots,10^{100}$원짜리 지폐를 이용해 $N$원을 지불하려고 한다. 지불하는 돈의 지폐 수와 거스름돈의 지폐 수의 합을 최소화하는 문제
$1 \le N \le 10^{18}$
거스름돈의 액수를 $x \ge 0$이라고 하면, $N+x$원을 지불하고 $x$원을 거슬러 주는 상황이라고 볼 수 있습니다. 즉, 적당한 음이 아닌 정수 $x$에 대해, $\text{digitsum}(N+x) + \text{digitsum}(x)$의 최솟값을 구하는 문제입니다. 가능한 모든 $x$에 대해 위 식을 계산하고 최솟값을 구하는 것은 불가능하므로 다른 방법을 생각해야 합니다.
$x$의 각 자리를 낮은 자리부터 하나씩 확정하는 방식으로 문제를 해결해 봅시다.
$N$의 $10^i$의 자리를 $S_i$라고 하고, $x$의 $10^i$의 자리를 $d$로 정하는 상황을 생각해 봅시다. 그러면 $\text{digitsum}(N+x)$는 $(S_i + d) \mod 10$ 만큼 증가하고, $\text{digitsum}(x)$는 $d$ 만큼 증가합니다. 또한, 만약 $S_i+d \ge 10$이었다면 받아올림이 발생해 $S_{i+1}$가 1 증가하게 됩니다.
따라서 다음과 같은 점화식을 세울 수 있습니다: $D(i, c) :=$ $x$의 $10^0, 10^1, 10^2, \cdots, 10^i$의 자리까지 결정했고, $10^i$의 자리에서 받아올림 발생 여부가 $c$일 때 가능한 $\text{digitsum}(N+x) + \text{digitsum}(x)$의 최솟값
$x$의 $10^i$의 자리를 $d$로 정하는 경우, $s = S_i + d + c$라고 하면 $D(i+1, [s\ge 10]) \leftarrow D(i, c) + (s \mod 10) + d$ 와 같이 상태 전이를 할 수 있습니다.
void Solve(){
cin >> S;
reverse(S.begin(), S.end());
S += "0";
memset(D, 0x3f, sizeof D);
D[0][0] = 0;
for(int i=0; i<S.size(); i++){
for(int c=0; c<2; c++){
if(D[i][c] == INF) continue;
for(int d=0; d<10; d++){
int sum = S[i] - '0' + d + c;
D[i+1][sum/10] = min(D[i+1][sum/10], D[i][c] + sum%10 + d);
}
}
}
cout << D[S.size()][0] << "\n";
}
E. Summer Vacation
$M$개의 구간이 있다. 쿼리로 $L, R$이 주어지면, 시작점이 $L$ 이상이고 끝점이 $R$ 이하인 구간만 이용해 만든 구간 그래프의 최대 독립 집합 크기를 구하는 문제
$1 \le M,Q \le 2\times 10^5$
쿼리가 없을 때는 구간들을 끝점 기준 오름차순으로 정렬한 뒤, 지금까지 선택한 구간들의 끝점보다 더 늦게 시작하는 구간을 선택하는 것을 반복해 해결할 수 있습니다.
void Naive(){
cin >> N >> M;
for(int i=1; i<=M; i++) cin >> A[i][0] >> A[i][1];
sort(A+1, A+M+1, [](const auto &a, const auto &b){ return a[1] < b[1]; });
int res = 0, lst = -1;
for(int i=1; i<=M; i++) if(lst < A[i][0]) res++, lst = A[i][1];
cout << res << "\n";
}
쿼리가 주어지더라도 “다음 구간”을 선택하는 방식은 변하지 않으므로, 먼저 $f(i) :=$ $i$번 구간 바로 다음에 선택할 구간의 번호를 전처리합시다. 이는 구간을 시작점 기준으로 정렬한 뒤, 뒤에서부터 보면서 현재 구간이 $I_i = [l_i, r_i]$라고 할 때 $r_i < l_j$ 이면서 $r_j$가 최소인 $j$를 구하면 되고, 세그먼트 트리를 이용해 $O(M \log N)$ 시간에 모두 계산할 수 있습니다.
pair<int,int> T[SZ<<1]; // Set(start, {end, index})
void Set(int x, pair<int,int> v){
for(x|=SZ; x; x>>=1) T[x] = min(T[x], v);
}
pair<int,int> Query(int l, int r){
pair<int,int> res(INF, INF);
for(l|=SZ, r|=SZ; l<=r; l>>=1, r>>=1){
if(l & 1) res = min(res, T[l++]);
if(~r & 1) res = min(res, T[r--]);
}
return res;
}
void Solve(){
cin >> N >> M >> Q;
for(int i=1; i<=M; i++) cin >> A[i][0] >> A[i][1];
sort(A+1, A+M+1);
fill(T, T+SZ*2, make_pair(INF, INF));
for(int i=M; i>=1; i--){
// // r[i]+1 <= l[j] 이면서 r[j]가 최소인 구간
auto [end,index] = Query(A[i][1]+1, N); // end = INF 면 다음 구간이 없음
if(end <= N) P[0][i] = index;
Set(A[i][0], {A[i][1], i});
}
// TODO
}
$f(i)$를 구했다면 쿼리를 처리하는 것은 어렵지 않습니다. 먼저, $l \le l_i$ 인 구간 중 $r_i$가 가장 작은 구간 $i$를 찾은 뒤, 구간의 끝점이 $r$ 이하라면 계속해서 $f(f(f(\cdots f(i)\cdots)))$처럼 $f$를 따라가면 됩니다. 이때 $f$를 따라간 횟수가 정답니 됩니다. 하지만 매번 $f$를 따라가도록 구현하면 쿼리마다 $O(M)$ 시간에 걸려 시간 제한 안에 문제를 풀 수 없습니다.
$f(i), f^2(i), f^4(i), f^8(i), \cdots$를 미리 전처리하면 각 쿼리를 $O(\log M)$ 시간에 처리할 수 있습니다. $f^{2^i}(i) = f^{2^{i-1}}(f^{2^{i-1}}(i))$라는 점을 이용하면 전처리 또한 $O(M \log M)$ 시간에 할 수 있습니다.
따라서 전체 시간 복잡도는 $O(M \log N + (M+Q) \log M)$입니다.
WF 2014, UCPC 2020 등에 출제된 적 있는 나름 유명한 테크닉입니다.
pair<int,int> T[SZ<<1];
void Set(int x, pair<int,int> v){
for(x|=SZ; x; x>>=1) T[x] = min(T[x], v);
}
pair<int,int> Query(int l, int r){
pair<int,int> res(MOD, MOD);
for(l|=SZ, r|=SZ; l<=r; l>>=1, r>>=1){
if(l & 1) res = min(res, T[l++]);
if(~r & 1) res = min(res, T[r--]);
}
return res;
}
int N, M, Q, P[22][202020];
array<int,2> A[202020];
void Solve(){
cin >> N >> M >> Q; A[0] = {MOD, MOD};
for(int i=1; i<=M; i++) cin >> A[i][0] >> A[i][1];
sort(A+1, A+M+1);
fill(T, T+SZ*2, make_pair(MOD,MOD));
for(int i=M; i>=1; i--){
auto [end,index] = Query(A[i][1]+1, N);
if(end <= N) P[0][i] = index;
Set(A[i][0], {A[i][1], i});
}
for(int i=1; i<22; i++) for(int j=1; j<=M; j++) P[i][j] = P[i-1][P[i-1][j]];
for(int q=1; q<=Q; q++){
int l, r; cin >> l >> r;
auto [end,p] = Query(l, r);
if(p == MOD || r < A[p][1]){ cout << "0\n"; continue; }
int res = 1;
for(int i=21; i>=0; i--) if(A[P[i][p]][1] <= r) res += 1 << i, p = P[i][p];
cout << res << "\n";
}
}
F. Set
길이가 $N$인 수열 $A$와 순열 $P$가 있다. 아래 조건이 성립하도록 $\lbrace1,2,\cdots,N \rbrace$의 부분 집합 $S$를 선택하려고 한다.
- $x,y\in S$ ($x<y$)면 $P_z=\min(P_x,P_{x+1},P_y)$ 인 $z$도 $z\in S$가 성립해야 함.
$K = 1, 2, \cdots, N$에 대해 크기가 $K$인 가능한 $S$ 중 $\sum_{i\in S} A_i$의 최솟값을 각각 구하는 문제
$1 \le N \le 5\,000$
길이가 $N$인 수열 $A$가 있을 때, 아래 조건을 만족하는 정점이 $N$개인 이진 트리를 카르테시안 트리라고 부릅니다.
- $x$가 $y$의 조상이라면 $x \le y$
- 트리의 중위 순회가 $1, 2, \cdots, N$
즉, 카르테시안 트리는 수열에서 최솟값이 있는 위치 $p$가 루트 정점이고, $p$보다 앞에 있는 인덱스는 왼쪽 서브 트리, 뒤에 있는 인덱스는 오른쪽 서브 트리에 넣은 트리입니다. 카르테시안 트리는 스택을 이용해 $O(N)$ 시간에 구축할 수 있습니다. (link)
$P_z = \min(P_x,P_{x+1}, \cdots, P_y)$는 카르테시안 트리에서 $z = LCA(x, y)$라는 것을 의미합니다. 따라서 문제에서 요구하는 $S$의 조건은, 어떤 두 정점을 선택했다면 두 정점의 LCA도 선택해야 한다는 것으로 해석할 수 있습니다.
$v$를 루트로 하는 서브 트리에서 $k$개의 정점을 선택했을 때 비용 최솟값을 $D(v, k)$라고 정의합시다. 만약 $v$의 양쪽 서브 트리에서 모두 1개 이상의 정점을 선택했다면 $v$를 무조건 선택해야 합니다. 따라서 상태 전이는 다음과 같이 만들 수 있습니다.
- $D(v, 0) \leftarrow 0$
- $D(v, 1) \leftarrow A_v$
- $D(v, k_1+k_2+1) \leftarrow D(l, k_1) + D(r, k_2) + A_v$
- $D(v, k) \leftarrow \min(D(l, k), D(r, k))$
$D(v)$를 계산할 때 길이가 최대 $N+1$인 두 배열의 convolution을 $O(N^2)$ 시간에 계산해야 하므로 전체 시간 복잡도가 $O(N^3)$일 것 같지만, 실제로는 $O(N^2)$입니다. 구체적으로, 크기가 각각 $A, B$인 서브 트리의 정보를 각각 $O(AB)$ 시간에 합칠 수 있으면 전체 시간 복잡도가 $O(N^2)$이 된다는 것을 증명할 수 있습니다.
$A\times B$는 왼쪽 서브 트리의 정점과 오른쪽 서브 트리의 정점을 짝짓는 경우의 수와 같습니다. 이때, 두 정점 $a \in A$와 $b \in B$는 $LCA(a, b)$에서만 정확히 한 번 만나게 되므로, 트리에서 $A\times B$의 합은 트리에서 임의의 두 정점을 선택하는 경우의 수와 같습니다. 따라서 트리의 형태와 관계 없이, 심지어 이진 트리가 아니더라도 항상 $O(N^2)$ 시간에 문제를 해결할 수 있습니다.
한국에서는 2019 KOI 고등부 3번에 이 테크닉이 출제되어서 많이 알려져 있습니다.
vector<ll> Conv(const vector<ll> &a, const vector<ll> &b){
// min-plus convolution
// c[k] = min a[i] + b[k-i]
vector<ll> res(a.size() + b.size() - 1, INF);
for(int i=0; i<a.size(); i++){
for(int j=0; j<b.size(); j++){
res[i+j] = min(res[i+j], a[i] + b[j]);
}
}
return res;
}
int Build(){
vector<int> stk;
for(int i=1; i<=N; i++){
int lst = 0;
while(!stk.empty() && P[stk.back()] > P[i]) lst = stk.back(), stk.pop_back();
if(!stk.empty()) R[stk.back()] = i, Par[i] = stk.back();
if(lst) L[i] = lst, Par[lst] = i;
stk.push_back(i);
}
return find(Par+1, Par+N+1, 0) - Par; // return root
}
vector<ll> DFS(int v){
if(v == 0) return {0};
auto lv = DFS(L[v]), rv = DFS(R[v]);
auto res = Conv(lv, rv);
for(auto &i : res) i += A[v];
res.insert(res.begin(), 0);
for(int i=0; i<lv.size(); i++) res[i] = min(res[i], lv[i]);
for(int i=0; i<rv.size(); i++) res[i] = min(res[i], rv[i]);
return res;
}
void Solve(){
cin >> N;
for(int i=1; i<=N; i++) cin >> P[i];
for(int i=1; i<=N; i++) cin >> A[i];
int root = Build();
auto res = DFS(root);
for(int i=1; i<=N; i++) cout << res[i] << " ";
cout << "\n";
}
G. Mouth
길이가 $N$인 수열 $A$가 주어진다. 쿼리로 두 정수 $i, v$가 주어지면, $A_i \leftarrow v$로 수정한 뒤에 아래 문제의 정답을 출력하는 문제
길이가 $N$인 수열 $B$가 있다. $B$의 모든 원소는 초기에 $0$이다. 원하는 정수 $x$ ($1 \le x \le N$)을 고른 뒤, 아래 연산을 원하는 만큼 반복한다.
- 연산: 현재 위치를 $y$라고 하자. $y-1, y, y+1$ 중 원하는 곳으로 이동한 뒤, $B_y$를 1 만큼 증가시킨다. 단, 수열 밖으로 나갈 수 없다
연산을 모두 끝낸 뒤, $\sum_{i=1}^N \vert A_i-B_i\vert$으로 가능한 최솟값을 출력
$1 \le N,Q \le 10^5$
$B$에서 $0$이 아닌 원소는 하나의 구간을 이루며, 그 구간 안에서는 값을 원하는 대로 만들 수 있습니다. 따라서 구간 $0$이 아닐 구간 $[l, r]$을 선택했다면, 비용은 다음과 같이 계산할 수 있습니다.
- $i < l$ 이거나 $i > r$ 이면 $B_i = 0$ 이므로 비용은 $A_i$
- $l \le i \le r$ 이고 $A_i > 0$ 이면 $B_i = A_i$ 로 설정할 수 있으므로 비용은 $0$
- $l \le i \le r$ 이고 $A_i = 0$ 이면 $B_i = 1$ 로 설정하는 게 최적이므로 비용은 $1$
- 따라서 총 비용은 $(\sum_{i=1}^{N} A_i) - (\sum_{i=l}^{r} A_i) + #\lbrace i; l\le i \le r, A_i = 0 \rbrace$
첫 번째 항은 $l, r$과 무관하므로 뒤에 있는 두 항의 합을 최소화해야 합니다. $W_i = [A_i=0] - A_i$라고 정의하면, $W_i$에서 합이 최소인 구간을 구하면 되고, 이는 값 업데이트가 있는 상황에서도 세그먼트 트리를 이용해 $O(\log N)$ 시간에 갱신과 최솟값 쿼리를 모두 수행할 수 있습니다.
구체적으로, 세그먼트 트리의 각 정점에서 아래 네 가지 정보를 관리하면 상수 시간에 두 정점을 합칠 수 있으므로, 각 쿼리를 $O(\log N)$ 시간에 처리할 수 있습니다.
- 첫 번째 원소를 포함하는 구간 최소 합
- 마지막 원소를 포함하는 구간 최소 합
- 구간 최소 합
- 모든 원소의 합
한국에서는 2014 KOI 중등부 3번에 이러한 자료구조를 사용하는 문제가 출제되어 많이 알려져 있습니다.
struct node{
ll l, r, mn, sum;
node() : node(INF, INF, INF, 0) {}
node(ll v) : node(v, v, v, v) {}
node(ll l, ll r, ll mn, ll sum) : l(l), r(r), mn(mn), sum(sum) {}
};
node operator + (const node &a, const node &b){
node res;
res.sum = a.sum + b.sum;
res.l = min(a.l, a.sum + b.l);
res.r = min(a.r + b.sum, b.r);
res.mn = min({a.mn, b.mn, a.r + b.l});
return res;
}
ll N, Q, A[101010], W[101010], S;
node T[SZ<<1];
void Update(int x, ll v){
for(T[x|=SZ]=v; x>>=1; ) T[x] = T[x<<1] + T[x<<1|1];
}
node Query(int l, int r){
node lv, rv;
for(l|=SZ, r|=SZ; l<=r; l>>=1, r>>=1){
if(l & 1) lv = lv + T[l++];
if(~r & 1) rv = T[r--] + rv;
}
return lv + rv;
}
void Solve(){
cin >> N >> Q;
for(int i=1; i<=N; i++) cin >> A[i];
for(int i=1; i<=N; i++) W[i] = A[i] == 0 ? 1 : -A[i];
for(int i=1; i<=N; i++) T[i|SZ] = {W[i], W[i], W[i], W[i]};
for(int i=SZ-1; i; i--) T[i] = T[i<<1] + T[i<<1|1];
S = accumulate(A+1, A+N+1, 0LL);
for(int q=1; q<=Q; q++){
ll x, v; cin >> x >> v;
S -= A[x]; S += v;
A[x] = v; W[x] = A[x] == 0 ? 1 : -A[x];
Update(x, W[x]);
cout << S + min(0LL, Query(1, N).mn) << "\n";
}
}
H. Coin
$N\times N$ 격자가 있다. 일부 칸에는 동전이 하나씩 있다. $(1, 1)$에서 시작해서 매번 오른쪽 또는 아래로만 이동하려고 한다. $x = 0, 1, 2, \cdots, 2N-2$에 대해, 동전을 정확히 $x$개 획득해서 갈 수 있는 칸의 개수를 출력하는 문제
$2 \le N \le 4\,000$; $(1, 1)$에 동전 없음
$(i, j)$로 갈 때 획득하는 코인의 최소 개수 $mn[i][j]$와 최대 개수 $mx[i][j]$는 $O(N^2)$ 시간에 쉽게 구할 수 있습니다. 그리고 놀랍게도 $mn[i][j] \le k \le mx[i][j]$인 모든 $k$에 대해, 코인을 정확히 $k$개만 획득하면서 $(1, 1)$에서 $(i, j)$로 가는 경로가 존재합니다. RD 를 DR로 바꾸거나, 반대로 DR을 RD로 바꾸면 기존 경로와 정확히 한 칸만 다른 경로를 만들 수 있다는 점을 생각해 보면 어렵지 않게 받아들일 수 있습니다.
따라서 $mn$과 $mx$를 계산한 뒤, 누적 합 배열을 이용하면 $O(N^2)$ 시간에 답을 구할 수 있습니다.
void Solve(){
cin >> N;
for(int i=1; i<=N; i++){
string s; cin >> s;
for(int j=1; j<=N; j++) A[i][j] = s[j-1] == '@';
}
memset(X, 0x3f, sizeof X);
memset(Y, 0xc0, sizeof Y);
X[1][1] = Y[1][1] = 0;
for(int i=1; i<=N; i++){
for(int j=1; j<=N; j++){
if(i + j == 2) continue;
X[i][j] = min(X[i-1][j], X[i][j-1]) + A[i][j];
Y[i][j] = max(Y[i-1][j], Y[i][j-1]) + A[i][j];
}
}
for(int i=1; i<=N; i++) for(int j=1; j<=N; j++) R[X[i][j]]++, R[Y[i][j]+1]--;
partial_sum(R, R+8080, R);
for(int i=0; i<=2*N-2; i++) cout << R[i] << "\n";
}
I. Update Positions
$N$개의 막대가 있다. $i$번째 막대의 길이는 $A_i$이다. 왼쪽에서 보면 $L$개, 오른쪽에서 보면 $R$개의 막대가 보이도록 막대를 배치하는 경우의 수를 구하는 문제. 단, 길이가 같은 막대는 구분하지 않는다.
$1 \le N \le 400$
막대의 길이가 모두 다를 때의 풀이를 먼저 알아봅시다.
길이가 긴 막대부터 하나씩 배치할 것입니다. 지금까지 $n$개의 막대를 배치했고, 왼쪽에서 $l$개, 오른쪽에서 $r$개 보이는 상황이라고 가정합시다.
만약 새로 추가하는 막대를 가장 왼쪽에 배치한다면 왼쪽에서 보이는 막대의 수가 1 증가하고, 가장 오른쪽에 배치하면 오른쪽에서 보이는 막대의 수가 1 증가합니다. 나머지 경우에는 보이는 막대의 수가 증가하지 않으며, 그런 경우는 총 $n-1$가지가 있습니다. 따라서 상태 전이는 다음과 같이 만들 수 있습니다.
- $D(n, l, r) \rightarrow D(n+1, l+1, r)$
- $D(n, l, r) \rightarrow D(n+1, l, r+1)$
- $D(n, l, r) \times (n-1) \rightarrow D(n+1, l, r)$
또는 $D(n,l,r) = D(n-1,l-1,r) + D(n-1,l,r-1) + (n-2)D(n-1,l,r)$ 으로 계산할 수도 있습니다. $O(N^3)$ 시간에 답을 구할 수 있습니다.
같은 길이의 막대가 여러 개 있을 때도 길이가 긴 막대부터 배치하는 건 똑같이 하는데, 길이가 같은 막대를 한 번에 모두 배치할 것입니다. 지금까지 $n$개의 막대를 배치했고, 이번에 길이가 같은 $c$개의 막대를 배치해야 한다고 합시다.
이때 $l$과 $r$을 모두 증가시키지 않기 위해서는 막대와 막대 사이에 있는 $n-1$개의 공간에 $c$개의 막대를 모두 배치해야 하고, 이런 경우는 총 $D(n,l,r)\times H(n-1,c)$가지 존재합니다. $l$만 증가시키기 위해서는 1개의 막대를 가장 왼쪽에 배치해야 하고, 나머지 $c-1$개의 막대는 $n$개의 공간에 자유롭게 배치하면 되므로 $D(n,l,r)\times H(n, c-1)$이 됩니다. $r$만 증가시키는 경우와 둘 다 증가시키는 경우도 비슷하게 계산할 수 있습니다.
따라서 상태 전이를 정리하면 다음과 같습니다. 여기에서 $H(n, k) = {n+k-1\choose k}$는 중복 조합을 의미합니다.
- $D(n, l, r) \times H(n-1, c) \rightarrow D(n+1,l,r)$
- $D(n,l,r) \times H(n, c-1) \rightarrow D(n+1, l+1, r)$
- $D(n,l,r) \times H(n, c-1) \rightarrow D(n+1, l, r+1)$
- $D(n,l,r) \times H(n+1, c-2) \rightarrow D(n+1, l+1, r+1)$
ll Pow(ll a, ll b){
ll res = 1;
for(; b; b>>=1, a=a*a%MOD) if(b & 1) res = res * a % MOD;
return res;
}
ll N, M, A[444], L, R, D[444][444][444];
ll Fac[444], Inv[444];
ll C(int n, int r){ return 0 <= r && r <= n ? Fac[n] * Inv[r] % MOD * Inv[n-r] % MOD : 0; }
ll H(int n, int r){ return C(n+r-1, r); }
void Solve(){
cin >> N >> L >> R;
for(int i=1; i<=N; i++) cin >> A[i];
Fac[0] = 1;
for(int i=1; i<=N; i++) Fac[i] = Fac[i-1] * i % MOD;
Inv[N] = Pow(Fac[N], MOD-2);
for(int i=N-1; i>=0; i--) Inv[i] = Inv[i+1] * (i+1) % MOD;
vector<int> V;
sort(A+1, A+N+1, greater<>());
for(int i=1, j=1; i<=N; i=j){
while(j <= N && A[i] == A[j]) j++;
V.push_back(j - i);
}
M = V.size();
for(int i=1; i<=M; i++) A[i] = V[i-1];
D[1][1][1] = 1;
for(int n=1, use=0; n<M; n++){
int c = A[n+1]; use += A[n];
for(int l=1; l<=n; l++){
for(int r=1; r<=n; r++){
const ll now = D[n][l][r];
if(now == 0) continue;
Add(D[n+1][l][r], H(use-1, c) * now % MOD);
Add(D[n+1][l+1][r], H(use, c-1) * now % MOD);
Add(D[n+1][l][r+1], H(use, c-1) * now % MOD);
Add(D[n+1][l+1][r+1], H(use+1, c-2) * now % MOD);
}
}
}
cout << D[M][L][R] << "\n";
}
J. Number and Total
길이가 $N$인 수열 $A$와 양의 정수 $S, T$가 주어진다. $c_1+c_2+\cdots c_N=S$, $A_1c_1+A_2c_2+\cdots+A_Nc_N=T$를 만족하는 음이 아닌 정수로 구성된 수열 $C = (c_1,c_2,\cdots,c_N)$의 개수를 구하는 문제
$1 \le N \le 20$; $1 \le S,T \le 10^{18}$; $1\le A_i \le 200$; $\sum A_i \le 200$
$c_i$를 이진법으로 생각해서 $c_i = \sum_e b_{i,e}2^e$ 처럼 나타냅시다. 그러면 이 문제는 각 $e$마다 어떤 $i$에 배치할지 선택하는, 즉 $B_e \subseteq \lbrace 1, 2, \cdots, N \rbrace$를 각 $e$에 대해 결정하는 문제로 생각할 수 있습니다. 조금 더 구체적으로, $X_e = \vert B_e\vert = \sum_i b_{i,e}$, $Y_e = \sum_{i\in B_e} A_i$ 라고 정의하면, $\sum_e X_e2^e = S$, $\sum_e Y_e2^e = T$가 성립하는 $B = (B_0, B_1, \cdots)$ 의 개수를 구하는 문제입니다. 이때 $0 \le X_e \le N \le 20$, $0 \le Y_e \le \sum A_i \le 200$ 입니다.
낮은 자리부터 차례대로 보면서, $D(i, c_S, c_T) := $ $S, T$의 $2^0, 2^1, \cdots, 2^i$의 자리까지 만들었고, $2^{i+1}$의 자리에서 $S, T$에 각각 $c_S, c_T$ 만큼의 받아올림이 발생하는 경우의 수라고 정의합시다. $D(59, 0, 0)$이 우리가 원하는 답입니다.
$2^{i+1}$의 자리에 $(X_{i+1}, Y_{i+1})$을 더하기 위해서는 $c_S$와 $c_T$가 각각 $c_S+X_{i+1}\equiv S[i+1] \pmod 2$, $c_T + Y_{i+1} \equiv T[i+1] \pmod 2$ 가 성립해야 하고, $\lfloor (c_S+X_{i+1})/2 \rfloor$, $\lfloor (c_T+Y_{i+1})/2 \rfloor$ 로 바뀝니다. 여기에서도 $c_S \le N \le 20$, $c_T \le \sum A_i \le 200$ 이 성립하므로, DP의 상태 공간은 $60 \times(N+1)\times (1+\sum A_i) = 60\times 21\times 201 = 253\,260$ 정도로 충분히 작습니다.
상태 전이를 위해 가능한 모든 $(X_e, Y_e)$를 순회할 때 $2^N$가지의 부분 집합을 모두 순회하는 것은 비효율적입니다. $i = 1, 2, \cdots, N$에 대해 $A_i$를 사용하는 경우와 사용하지 않는 경우를 고려하면 되므로, 0/1 knapsack과 같은 식으로 처리하면, $i+1$번째 비트에서 값이 $c_S+X_{i+1}, c_T+Y_{i+1}$이 되도록 만드는 경우의 수 $E(c_S+X_{i+1}, c_T+Y_{i+1})$를 $O(N^2\sum A_i)$ 시간에 셀 수 있습니다.
이후 위에서 언급한 조건을 만족하는 $(c_S+X_{i+1}, c_T+Y_{i+1})$에 대해서만 $D(i+1, \ast, \ast)$로 값을 옮기면, $D(i, \ast, \ast)$ 에서 $D(i+1, \ast, \ast)$로의 전이를 $O(N^2\sum A_i + N\sum A_i)$ 시간에 모두 처리할 수 있습니다.
전체 시간 복잡도는 $O(N^2 \log \max(S,T) \sum A_i)$입니다.
bool Check(int pos, int c_s, int c_t){
return c_s % 2 == S[pos] && c_t % 2 == T[pos];
}
void Solve(){
cin >> N >> _S >> _T;
for(int i=1; i<=N; i++) cin >> A[i];
K = accumulate(A+1, A+N+1, 0);
for(int i=1; i<=60; i++) S[i] = _S >> i-1 & 1;
for(int i=1; i<=60; i++) T[i] = _T >> i-1 & 1;
D[0][0][0] = 1;
for(int n=0; n<60; n++){
memcpy(E, D[n], sizeof E);
for(int i=1; i<=N; i++) for(int s=N+N; s>=0; s--) for(int t=K+K; t>=0; t--)
if(E[s][t]) Add(E[s+1][t+A[i]], E[s][t]);
for(int s=0; s<=N+N; s++) for(int t=0; t<=K+K; t++)
if(Check(n+1, s, t)) Add(D[n+1][s/2][t/2], E[s][t]);
}
cout << D[60][0][0] << "\n";
}
K. Addition and Subtraction
길이가 $N$인 수열 $A$가 주어진다. 초깃값이 $0$인 정수 변수 $x$가 있고, 아래 연산을 $i = 1, 2, \cdots, N$에 대해 차례대로 한 번씩 수행해야 한다.
- 연산: $x$를 $x+A_i$, $\vert x-A_i\vert$, $x$ 중 하나로 바꾼다.
$N$번의 연산을 모두 수행했을 때 가능한 결과로 가능한 수의 개수를 구하는 문제
$1 \le N \le 5\times 10^5$; $1 \le A_i \le 2\times 10^6$; $\sum A_i \le 2\times 10^6$
편의상 $\sum A_i = X$라고 정의합시다.
만들 수 있는 수가 어떤 형태인지를 먼저 파악해야 합니다. 수학적 귀납법을 이용하면, 만들 수 있는 수의 필요 충분 조건이 $\vert \sum_{i=1}^N c_iA_i \vert$ 라는 것을 알 수 있습니다. (단, $c_i \in \lbrace -1, 0, 1 \rbrace$) 또한, 연산 순서를 마음대로 바꾸더라도 만들 수 있는 값의 집합은 바뀌지 않습니다.
일반적으로 절댓값을 다루는 것은 까다롭기 때문에, $\sum c_iA_i$로 만들 수 있는 값을 모두 구한 다음 $x$ 또는 $-x$를 만들 수 있는지 확인하는 식으로 문제를 해결할 것입니다.
$D(i, x) := $ $A_1, \cdots, A_i$를 이용해 $x$를 만들 수 있으면 1, 아니면 0 으로 정의합시다. $D(i, x) = D(i-1, x-A_i) \text{ or } D(i-1, x+A_i)$로 계산할 수 있지만, 시간이 너무 오래 걸립니다. $N \le 5\times 10^5$, $X \le 2\times 10^6$으로 둘 모두 너무 큰 것이 문제입니다.
문제를 배낭 문제의 관점에서 다시 생각해 봅시다. $A_i$가 같은 것끼리 모으면, 각 물건에 사용 횟수 제한이 있는 배낭 문제라고 생각할 수 있습니다. 물건마다 사용 횟수 제한이 있는 배낭 문제는 각 물건을 1개, 2개, 4개, 8개, … 짜리 덩어리로 묶으면, $O(\log A_i)$개의 덩어리를 각각 0번 또는 1번 사용하는 배낭 문제로 바꿀 수 있습니다. 또한, 문제에 $\sum A_i = X \le 2\times 10^6$ 조건이 있으므로 서로 다른 $A_i$의 값은 최대 약 $\sqrt{2X} = \sqrt{4\times 10^6}$개밖에 존재하지 않습니다.
$M (\in O(\sqrt X \log X))$개의 물건을 각각 최대 한 번씩 사용할 수 있을 때, 무게의 합을 특정 값으로 만들 수 있는지 판단하는 건 bitset을 이용해 $O(MX/64)$ 시간에 할 수 있습니다. 구체적으로 길이가 $2X+1$인 비트셋 $B$를 만든 뒤, 무게가 $w$인 물건을 처리할 때 $B \leftarrow B \text{ or } (B»w) \text{ or } (B«w)$ 와 같이 갱신하면 됩니다.
$M \le \sqrt X \log X$ 이므로 전체 시간 복잡도는 $O(N \log X + X \sqrt X \log X / 64)$ 입니다.
constexpr int X = 2'000'000;
int N, A[505050], S;
vector<int> V;
bitset<4'000'001> D;
void Solve(){
cin >> N;
for(int i=1; i<=N; i++) cin >> A[i];
S = accumulate(A+1, A+N+1, 0);
sort(A+1, A+N+1);
for(int i=1, j=1; i<=N; i=j){
while(j <= N && A[i] == A[j]) j++;
int cnt = j - i;
for(int k=1; k<=cnt; k*=2) V.push_back(A[i] * k), cnt -= k;
if(cnt > 0) V.push_back(A[i] * cnt);
}
D[X] = 1;
for(auto i : V) D = D | (D >> i) | (D << i);
int res = 0;
for(int i=0; i<=S; i++) res += D[X+i] || D[X-i];
cout << res << "\n";
}
수열 $A$에서 값이 같은 원소끼리 묶은 결과를 $\lbrace (v_i, c_i) \rbrace$ 라고 합시다. 값이 $v_i$인 원소가 $c_i$개 있다는 것을 의미하고, $v_i$는 모두 서로 다르며, 당연히 $\sum v_ic_i = \sum A_i$입니다. 순서쌍의 개수는 최대 $O(\sqrt X)$개입니다.
위에서는 값이 같은 원소를 $c_i = 1 + 2 + 4 + 8 + \cdots$이 되도록 $\lfloor \log_2 c_i \rfloor + 1$개의 덩어리로 쪼갠 뒤, 덩어리의 개수 $M = \sum \lfloor \log_2 c_i \rfloor + 1$의 상한을 $O(\sqrt X \log X)$라고 했습니다. 하지만 실제로는 $M \in O(\sqrt X)$임을 증명할 수 있습니다.
앞에서 본 것처럼 $c_i \ge 1$인 순서쌍은 최대 $O(\sqrt X)$개입니다. 비슷하게, $c_i \ge 2$인 순서쌍은 최대 $O(\sqrt {X/2})$개만 존재할 수 있고, $c_i \ge 4$인 순서쌍은 최대 $O(\sqrt{X/4})$개 존재할 수 있습니다. 즉, $c_i \ge 2^k$인 순서쌍은 최대 $O(\sqrt{X/2^k})$개 존재할 수 있습니다. 따라서 $M = \sum \lfloor \log_2 c_i \rfloor + 1 \in O(\sum_{k=0}^{\infty} \sqrt{\frac{X}{2^k}}) = O(\sqrt X)$ 가 성립합니다.
전체 시간 복잡도는 $O(N + X \sqrt X / 64)$가 됩니다.
같은 테크닉을 사용하는 문제로는 ABC269G, 2021 SWERC K번 등이 있습니다.
L. LCM
길이가 $N$인 순열 $A$가 주어진다. $1 \le i < j \le N$인 두 정수 $i, j$에 대해, $i$에서 $j$로 가는 간선이 $\text{LCM}(i,j)$개 있는 DAG를 생각하자. $v = 2, 3, \cdots, N$에 대해, $1$번 정점에서 $v$번 정점으로 가는 경로의 수를 각각 구하는 문제
$2 \le N \le 2\times 10^5$
$1$번 정점에서 $v$번 정점까지 가는 경로의 수를 $D(v)$라고 정의합시다. $D(v) = \sum_{i<v} LCM(A_v,A_i)\times D(i)$ 입니다. $LCM(a,b) = ab/GCD(a,b)$이므로, $D(v) = A_v\sum_{i<v}\frac{A_iD(i)}{GCD(A_v,A_i)}$ 로 나타낼 수 있습니다. 분모에 있는 gcd를 $A_v$와 $A_i$로 갈라야 $O(N^2)$보다 빠르게 계산할 수 있어 보입니다.
뫼비우스 반전 공식(mobius inversion foluma)는 양의 정수 집합을 정의역으로 하는 두 함수 $f,g$에 대해 아래 두 조건이 동치임을 알려줍니다. 이때 $\mu$는 뫼비우스 함수입니다.
- $f(n) = \sum_{d\vert n} g(d)$
- $g(n) = \sum_{d\vert n} \mu(n/d)f(d)$
$f(n) = 1/n$으로 두면 $g(n) = \sum_{d\vert n} \frac{\mu(n/d)}{d}$ 이고, 따라서 $f(n) = \frac{1}{n} = \sum_{d\vert n} g(d) = \sum_{d\vert n} \sum_{e\vert d} \frac{\mu(d/e)}{e}$ 가 성립합니다. $n$에 $GCD(A_v,A_i)$를 대입하면, $\frac{1}{GCD(A_v,A_i)}=\sum_{d\vert A_v,\ d\vert A_i} g(d)$로 나타낼 수 있습니다.
이를 이용해 점화식을 다시 작성해 봅시다.
$D(v) = A_v \sum_{i<v} A_iD(i) \times \sum_{d\vert A_v,\ d\vert A_i} g(d)$
시그마 순서를 적절히 조절하면
$D(v) = A_v\sum_{d\vert A_v}g(d)\times \sum_{i<v,\ d\vert A_i} A_iD(i)$
안쪽 시그마를 $S(d)$ 로 묶으면 $D(v) = A_v\sum_{d\vert A_v}g(d)S(d)$ 가 됩니다.
$\mu(\ast)$는 $O(N)$, $g(\ast)$는 $O(N \log N)$ 시간에 계산할 수 있습니다. $D(v)$ 하나는 $O(\sigma(A_v))$ 시간에 계산할 수 있고, $D(v)$의 값이 확정된 후에 $S(\ast)$를 $O(N/A_v)$ 시간에 갱신할 수 있습니다.
$A$는 길이가 $N$인 순열이므로 $\sum_{i=1}^{N} \sigma(A_i) = \sum_{i=1}^{N} \lfloor N/A_i \rfloor \in O(N \log N)$입니다. 따라서 전체 문제를 $O(N \log N)$ 시간에 해결할 수 있습니다.
// f[n] = 1/n
// g[n] = \sum_{d|n} mu[n/d]*f[d] = \sum_{d|n} mu[n/d]/d
// f[n] = \sum_{d|n} g[d]
int sp[MX+1], mu[MX+1];
vector<int> primes, factors[MX+1];
ll inv[MX+1], g[MX+1];
void Init(int sz=MX){
mu[1] = 1;
for(int i=2; i<=sz; i++){
if(!sp[i]){ primes.push_back(i); sp[i]= i; mu[i] = -1; }
for(auto j : primes){
if(i * j > sz) break;
sp[i*j] = j;
if(i % j == 0){ mu[i*j] = 0; break; }
mu[i*j] = mu[i] * mu[j];
}
}
inv[1] = 1;
for(int i=2; i<=sz; i++) inv[i] = MOD - MOD/i * inv[MOD%i] % MOD;
for(int d=1; d<=sz; d++) for(int n=d; n<=sz; n+=d) factors[n].push_back(d);
for(int d=1; d<=sz; d++) for(int n=d; n<=sz; n+=d) g[n] = (g[n] + mu[n/d] * inv[d] + MOD) % MOD;
}
ll N, A[MX+1], D[MX+1], S[MX+1];
void Solve(){
cin >> N;
for(int i=1; i<=N; i++) cin >> A[i];
// D[v] = A[v] \sum_{d|A[v]} g[d] * S[d]
// S[d] = \sum_{d|A[i]} A[i] * D[i]
Init();
auto upd = [&](int i) -> void {
for(auto d : factors[A[i]]) S[d] = (S[d] + A[i] * D[i]) % MOD;
};
D[1] = 1; upd(1);
for(int v=2; v<=N; v++){
for(auto d : factors[A[v]]) D[v] = (D[v] + g[d] * S[d]) % MOD;
D[v] = A[v] * D[v] % MOD;
upd(v);
}
for(int i=2; i<=N; i++) cout << D[i] << "\n";
}
M. Numeral
1-9 숫자로 구성된 길이가 $2^N$인 문자열 $S$가 주어진다. $0 \le n < 2^N$인 정수 $n$에 대해, $f(n)$을 다음과 같이 정의하자.
- $n\ \text{OR}\ i = n$인 $i$를 각각 $i_1 < i_2 < \cdots < i_k$라고 하자.
- $S$의 $(i_1+1)$번째 문자, $(i_2+1)$번째 문자, $\cdots$를 이어붙인 문자열을 $T$라고 하자.
- $T$를 십진법으로 해석한 값을 $X$라고 할 때, $f(X) = X \mod 998244353$
$\sum_{n=0}^{2^N-1}(f(n)\ \text{XOR}\ n)$을 구하는 문제
$1 \le N \le 22$
$n\ \text{OR}\ i = n$ 은 $i$가 $n$의 부분 집합(서브마스크)임을 의미합니다. $n$의 서브마스크를 직접 순회하면서 답을 계산하면, $0 \le n < 2^N$인 모든 $n$의 서브마스크 개수의 합은 $3^N$이므로 시간 복잡도 또한 $O(3^N)$이 됩니다. 이는 이항 정리를 이용해 증명할 수 있습니다.
구체적으로, 크기가 $k$인 집합은 $n \choose k$개 있고, 크기가 $k$인 집합의 부분 집합은 $2^k$개 있으므로 $\sum_{k=0}^{n} {n \choose k} \times 2^k$가 되는데, 이항 정리를 이용하면 $(1+2)^N = 3^N$이 됩니다.
void Naive(){
cin >> N >> S; K = 1 << N;
ll res = 0;
for(int bit=0; bit<(1<<N); bit++){
string t;
for(int sub=bit; sub; sub=(sub-1)&bit) t += S[sub];
t += S[0];
reverse(t.begin(), t.end());
ll now = 0;
for(auto c : t) now = (now * 10 + c - '0') % MOD;
res += now ^ bit;
}
cout << res << "\n";
}
하지만 $N \le 22$ 이므로 $3^N$보다 빠르게 해결해야 합니다. 이런 류의 문제는 보통 SOS DP 라는 테크닉을 이용해 해결할 수 있습니다.
각 마스크 $bit$에 대해, $bit$의 모든 서브마스크 $i$를 오름차순으로 보면서 $S_i$를 이어붙인 문자열 $T_{bit}$를 생각합시다. 모든 $bit$에 대해 $T_{bit}$를 직접 계산하는 것은 비효율적이기 때문에 문자열의 길이와, 문자열을 십진법으로 해석한 값을 998244353으로 나눈 나머지만 저장할 것입니다. 이 두 가지 정보만 갖고 있더라도 두 문자열 $a, b$를 이어붙이는 연산은 $a \times 10^{\vert b\vert} + b \mod 998244353$으로 상수 시간에 계산할 수 있습니다.
struct Info{
ll len, val;
Info() : Info(0, 0) {}
Info(ll len, ll val) : len(len), val(val) {}
};
Info operator + (const Info &a, const Info &b){
return {a.len + b.len, (a.val * P[b.len] + b.val) % MOD};
} // P[i] = 10^i mod 998244353
이제 $T_{bit}$의 정보 $D(bit)$를 계산하는 방법을 알아봅시다. 처음에는 $D(bit) = \lbrace 1, S_i\rbrace$에서 시작합니다. 이 상태에서 낮은 비트부터 하나씩 보면서, 해당 비트가 켜져 있는 마스크에 대해 $D(bit) = D(bit-2^i) + D(bit)$를 계산하면 우리가 원하던 $i$를 오름차순으로 보면서 $S_i$를 이어붙인 문자열을 얻을 수 있습니다.
즉, 다음과 같은 반복문을 이용해 우리가 원하는 정보를 얻을 수 있습니다.
for(int i=0; i<N; i++){
for(int bit=0; bit<(1<<N); bit++){
if(bit >> i & 1) D[bit] = D[bit^(1<<i)] + D[bit];
}
}
이 반복문이 어떻게 중복 없이 각 서브마스크를 정확히 한 번씩만 반영하는지 궁금할 수 있는데, 각 차원의 길이가 2인 $N$차원 누적 합 배열이라고 생각하면 어느 정도 받아들일 수 있을 것입니다. 더 자세한 내용이 궁금하다면 SOS DP 또는 Sum of Subset DP라는 키워드로 검색해 보면 많은 정보를 얻을 수 있을 것입니다.
ll N, K, P[(1<<22)+1];
string S;
Info D[1<<22];
void Solve(){
cin >> N >> S; K = 1 << N;
P[0] = 1; for(int i=1; i<=K; i++) P[i] = P[i-1] * 10 % MOD;
for(int i=0; i<K; i++) D[i] = {1, S[i] - '0'};
for(int i=0; i<N; i++) for(int bit=0; bit<K; bit++) if(bit >> i & 1) D[bit] = D[bit^(1<<i)] + D[bit];
ll res = 0;
for(int i=0; i<K; i++) res += D[i].val ^ i;
cout << res << "\n";
}
N. Knapsack
$N$가지 종류의 물건이 무한히 많이 있다. $i$번째 물건의 무게는 $i$, 가치는 $v_i$이다. 쿼리로 $W$가 주어지면, 무게의 합이 정확히 $W$가 되도록 물건을 선택했을 때 가능한 가치 합의 최댓값을 출력하는 문제
$1 \le N \le 4\,000$; $1 \le Q \le 2\times 10^5$; $1 \le W \le 10^9$
Subtask 1. $N \le 300$
무게의 합이 정확히 $w$가 되도록 물건을 선택했을 때 가능한 가치 합의 최댓값을 $D(w)$라고 정의합시다. 또한, 가성비가 가장 좋은 물건, 즉 $v_i / i$가 최대인 물건을 $k$라고 합시다. $w$가 충분히 크다면 $D(w) = D(w-k) + v_k$가 성립할 것입니다. 위 식이 성립할 $w$의 하한을 구해 봅시다.
$1 \le i \le N$에 대해 $v_k/k \ge v_i/i$가 성립하므로, $w \ge LCM(k,i)$ 라면 무게가 $i$인 물건을 $k/GCD(k,i)$개 사용하는 것보다 무게가 $k$인 물건을 $i/GCD(k,i)$개 사용하는 것이 항상 이득입니다. 따라서 $w \ge \max_i LCM(k,i)$ 라면 항상 $D(w) = D(w-k) + v_k$가 성립합니다. $1 \le i \le N$에 대해 $LCM(k,i) \le k\times i \le N^2$이 성립하므로 $w \ge N^2$ 이면 항상 해당 식이 성립한다는 것을 알 수 있습니다.
따라서 $w \le N^2$ 범위에서 DP를 이용해 $O(N^3)$ 시간에 정확한 답을 계산한 뒤, $N^2$보다 큰 $w$에 대해서는 $A_k\times \lceil \frac{w-N^2}{k} \rceil + D(w-k\times \lceil \frac{w-N^2}{k} \rceil)$를 계산해서 출력하면 됩니다.
void Solve(){
cin >> N >> Q;
for(int i=1; i<=N; i++) cin >> A[i];
memset(D, 0xc0, sizeof D); D[0] = 0;
for(int i=1; i<=N; i++) for(int j=i; j<=N*N; j++) D[j] = max(D[j], D[j-i] + A[i]);
ll k = 1;
for(int i=2; i<=N; i++) if(A[i] * k > A[k] * i) k = i;
for(int q=1; q<=Q; q++){
int w; cin >> w;
if(w <= N*N){ cout << D[w] << "\n"; continue; }
ll t = (w - N*N + k - 1) / k; // ceil (w-n^2) / k
cout << A[k] * t + D[w-t*k] << "\n";
}
}
Subtask 2. $N \le 4\,000$
Chan, He 의 “More on change-making and related problems” 논문(link)에서 Section 5. All-capacities unbounded knapsack 문단에 따르면, DP 전처리 과정을 $O(N^2 \log N^2)$에 할 수 있다고 합니다.
구체적으로, 모든 물건을 $v_i/w_i$ 내림차순으로 정렬한 뒤, 아래 점화식을 이용해 계산하면 됩니다. 증명은 생략합니다.
\[\displaystyle D(w) = \max_{1 \le i \le \lceil3n^2/w\rceil; w_i\le w} D(w-w_i)+v_i\]
시간 복잡도는 $\sum_{k=1}^{N^2} \min(N, \frac{3N^2}{k}) \le \sum_{k=1}^N N + \sum_{k=N+1}^{N^2} \frac{3N^2}{k} \approx N^2 + 3N^2 \int_{N+1}^{N^2} \frac{1}{x} dx \in O(N^2 \log N)$입니다.
void Solve(){
cin >> N >> Q;
for(int i=1; i<=N; i++) cin >> A[i];
vector<int> O(N+1);
iota(O.begin(), O.end(), 0);
sort(O.begin()+1, O.end(), [](int x, int y){
return A[x] * y > A[y] * x;
});
ll k = O[1];
memset(D, 0xc0, sizeof D); D[0] = 0;
for(int w=1; w<=N*N; w++){
int limit = min(N, (3*N*N + w - 1) / w); // ceil(3n^2/w)
for(int i=1; i<=limit; i++){
if(O[i] <= w) D[w] = max(D[w], D[w-O[i]] + A[O[i]]);
}
}
for(int q=1; q<=Q; q++){
int w; cin >> w;
if(w <= N*N){ cout << D[w] << "\n"; continue; }
ll t = (w - N*N + k - 1) / k; // ceil (w-n^2) / k
cout << A[k] * t + D[w-t*k] << "\n";
}
}
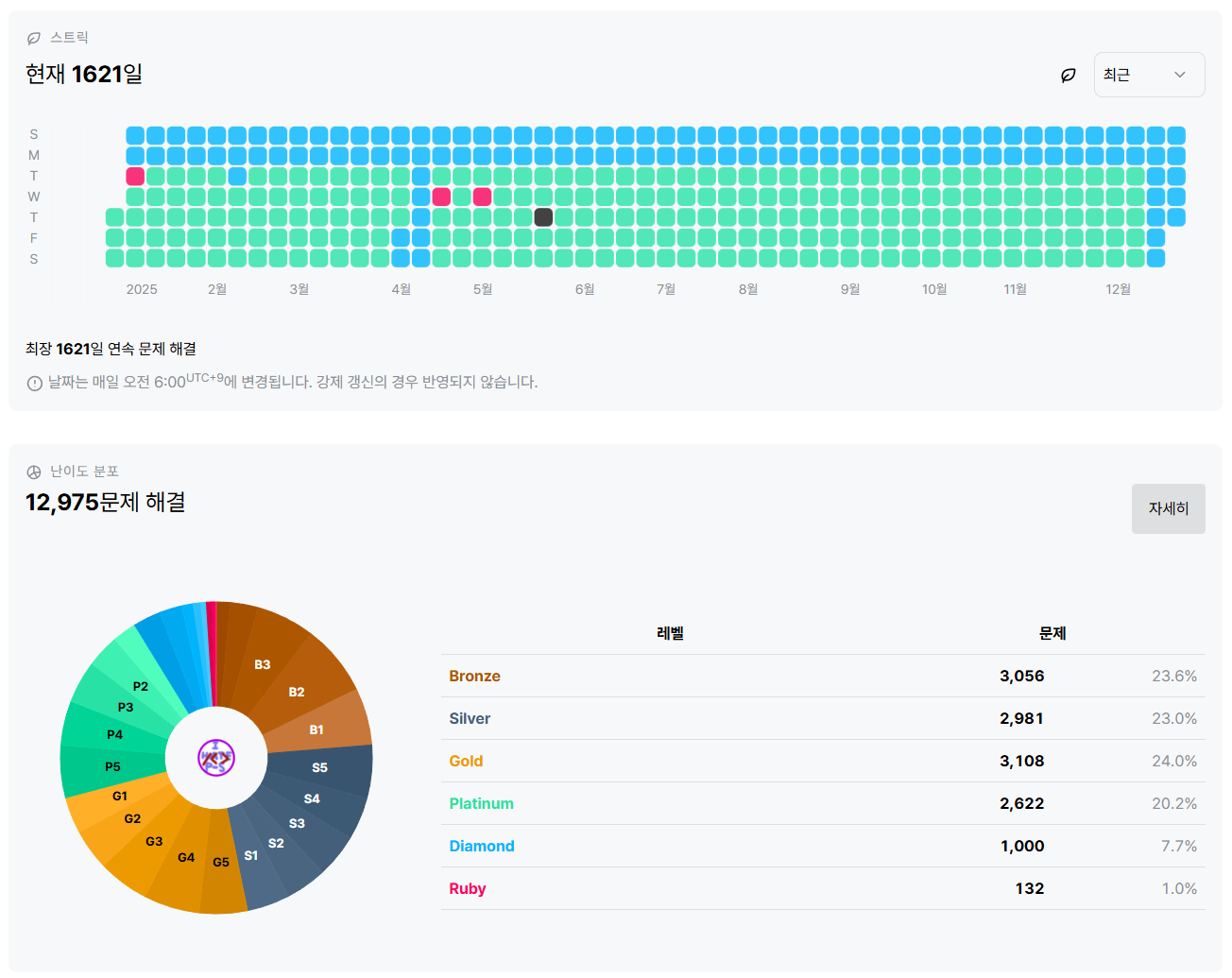
 올해도 어김없이 대회를 열었습니다.
올해도 어김없이 대회를 열었습니다.