PS 원툴 대학생의 네이버 인턴 생존기… 인 줄 알았지만 Yorkie 프로젝트 소개가 되어버린 글
목차
- 인턴 지원
- Yorkie 프로젝트 소개
- 기억력 문제
- Yorkie 자료구조 소개
- 고쳐야 할 문제
- RHT 동시 편집 지원
- Table Driven Test 도입
- Garbage collector 수정
- Tree 연산 소개
- 트리 동시 편집 테스트 프레임워크
- 이진 탐색 트리 개선 방안 제안
- 후기
처음에 예상했던 것보다 글이 훨씬 많이 길어졌습니다. PC 화면으로 보시는 분들은 오른쪽 사이드 바를 이용해 원하는 문단으로 넘어갈 수 있습니다.
인턴 지원
평소와 같이 침대에 누워서 핸드폰을 보고 있었는데 우연히 네이버 Yorkie TF 에서 인턴을 모집한다는 소식(링크)을 듣고 3일 만에 자소서를 휘갈겨 써서 제출했습니다.
인터넷을 보면 PS만 한 사람은 취업을 못 한다는 이야기가 많이 보이고 보통 이런 글에는 자소서/이력서에 백준 등수를 적지 말라는 조언도 함께 붙곤 합니다. 하지만 저는 주변 지인들이 좋은 회사에 취업한 것을 많이 보았기 때문에 당당하게 자소서 문항 3개를 전부 PS로 도배하는 것으로 모자라서 아예 첫 번째 줄에 BOJ 등수를 적었습니다. 물론 문제 푸는 얘기만 3000글자씩 적은 건 아니고, PS 하면서 상 받은 이야기, PS 하면서 사람 가르친 이야기, PS 하면서 전공과목 날로 먹은 이야기 등등 다양하게 적긴 했습니다.
놀랍게도(?) 서류 합격해서 코딩 테스트 응시 기회를 얻었습니다. 3문제 출제되었고 다 푸는데 10~15분 정도 걸렸습니다. 제출 버튼 눌러도 채점 결과 안 알려주면서 더 이상 코드 수정을 못 하게 하는 게 인상적이었습니다. 코딩 테스트에서 떨어질 일은 없으니 코딩 테스트가 끝나자마자 면접 준비를 시작했습니다. 면접 준비를 위해 채용 공고(잡코리아)를 다시 읽어 보니…
자격 요건: 자료구조, 알고리즘, 프로그래밍언어, OS 등 전산 기초를 공부하신 분 / Go, Rust, C/C++, JS, Python 등 하나 이상의 프로그래밍 언어에 익숙한 사용이 가능하신 분
우대 사항: 논리 시계나 CRDT를 이용한 대규모 분산 시스템 개발에 관심이 있으신 분 / … (후략)
어… 제가 학교에서 A+ 받은 과목이 몇 개 없는데 딱 A+ 받은 과목들만 모여있었습니다. 동시 편집 기능을 개발하는 팀인 만큼 동시성 관련 내용을 물어볼 것 같아서 뮤텍스와 세마포어를 간단하게 복습하고, Yorkie에서 splay tree랑 rope 같은 자료구조를 사용하는 것 같아서 BBST(balanced binary search tree)도 다시 봤습니다. 우대 사항에 논리 시계나 대규모 분산 시스템이 언급되어 있어서 남는 시간에는 “가상 면접 사례로 배우는 대규모 시스템 설계 기초” 책을 조금씩 읽었습니다.
면접은 30분 정도 진행되었고, 자세하게 말할 수는 없지만 숭실대 특기자 전형 면접보다도 더 편안한 분위기에서 제가 좋아하는 PS와 ICPC 이야기만 잔뜩 하다가 나왔습니다. 상상 속에 있던 회사 면접과는 전혀 다르게, 이게 면접이 맞나 싶을 정도로 신기하게 진행되었습니다. 동아리나 기업에서 사람들 대상으로 강의했던 경험이 큰 도움이 되었던 것 같습니다. 떨어질 확률보다 붙을 확률이 조금 더 높다고 생각했고, 면접 일주일 정도 뒤에 합격 통보를 받았습니다. 참고로 면접 준비하면서 공부한 것은 아무 쓸모가 없었습니다.
면접 때 옷을 어떻게 입어야 하는지 몰라서 열심히 검색했었는데 쓸만한 결과가 나오지 않아서 많이 고민했었습니다. 저는 잠옷 입고 면접 봐서 붙었으니 이 글을 보는 분들은 고민하지 말고 편한 복장으로 면접에 들어가시길 바랍니다.
Yorkie 프로젝트 소개
저는 인턴십 기간 동안 실시간 협업을 위한 CRDT 기반 동시 편집 오픈소스 프레임워크 Yorkie(GitHub) 개발에 참여했습니다. Yorkie 프로젝트를 구경하다 보면 다양한 토픽을 볼 수 있는데, 저는 동시 편집 지원을 위한 CRDT 자료구조(RHT, RGA tree 등)와 이를 지원하기 위한 기초적인 여러 자료구조(Splay tree, Red-black tree, Hash table 등)에 가장 관심이 있었습니다. 이 밖에도 CRDT에서 사용하기 위한 논리 시계(Lamport timestamp, Vector clock, 관련 PR), 문서 데이터의 효율적인 저장을 위한 데이터베이스 샤딩(관련 이슈)같은 학교 강의에서 어렴풋이 들었던 개념들도 실제로 활용하고 있고, Yorkie의 동시 편집 기능에 GPT와 같은 LLM을 붙인 마크다운 문서 편집기 CodePair(GitHub)를 만들기도 합니다.
주변에서 “네이버에서 어떤 일을 했냐?” 라고 물어보면 주로 “구글 독스 같은 것을 만들었다” 라고 대답하고 있습니다. 예전부터 구글 독스를 많이 써와서 별생각 없이 당연하다는 듯이 사용하고 있었는데, 인턴을 하면서 구글 독스는 온갖 기술의 결정체라는 것을 깨닫게 되었습니다. 진짜 어떻게 만든 거지…
기억력 문제
사실 이 글을 작성하기 시작할 때는 1주차부터 8주차까지 어떤 생각을 갖고 어떤 작업을 했는지 적으려고 했지만, 인턴 기간이 끝난 지 한 달도 넘게 지나서 기억이 잘 안 나기도 하고 블로그에 어디까지 작성해도 되는지를 모르겠어서… 그냥 발표 준비하면서 만들었던 자료 중심으로 설명하려고 합니다. 다 쓰고 보니 인턴 후기보다는 CRDT와 Yorkie 프로젝트 소개에 가까운 것 같습니다.
Yorkie 자료구조 소개
Yorkie는 다양한 자료구조가 맞물려 돌아가고 있습니다. (data structure design docs 참고)

Yorkie는 자료구조를 (1) 실제로 사용자가 다루게 될 문서 레벨의 JSON 형태의 자료구조, (2) 문서의 동시 편집 연산을 지원하는 CRDT 자료구조, (3) CRDT 자료구조의 밑에서 돌아가는 기본 자료구조까지 총 3가지로 구분하고 있습니다. 예를 들어 사용자가 Text 형태인 객체의 특정 구간에 bold 속성을 적용한다고 하면 Text객체의 내용물을 저장하고 있는 RGATreeSplit은 속성을 적용할 노드들의 구간을 구해야 하는데, 이때 BBST인 SplayTree나 LLRBTree를 이용해 효율적으로 구간을 모으는 방식으로 연산이 진행됩니다. SplayTree와 LLRBTree와 같은 기본 자료구조는 동시 편집을 고려하지 않은 채로 만들어져 있으며, 연산의 우선순위나 오프셋 등을 조정해서 동시 편집 지원을 보장하는 부분은 CRDT 자료구조에서 담당하고, 유저가 사용할 인터페이스는 JSON-Like 자료구조에서 제공하는 방식입니다.
ElementRHT와 RHT에서 보이는 RHT는 Replicated Hash Table의 줄임말로, 동시 편집을 지원하는 해시 테이블입니다. ElementRHT는 JSON-Like Object의 멤버를 관리하는 자료구조로 문자열 → 객체 매핑을 수행하고, RHT는 노드의 attribute를 관리하는 자료구조로 문자열 → 문자열 매핑을 수행합니다.
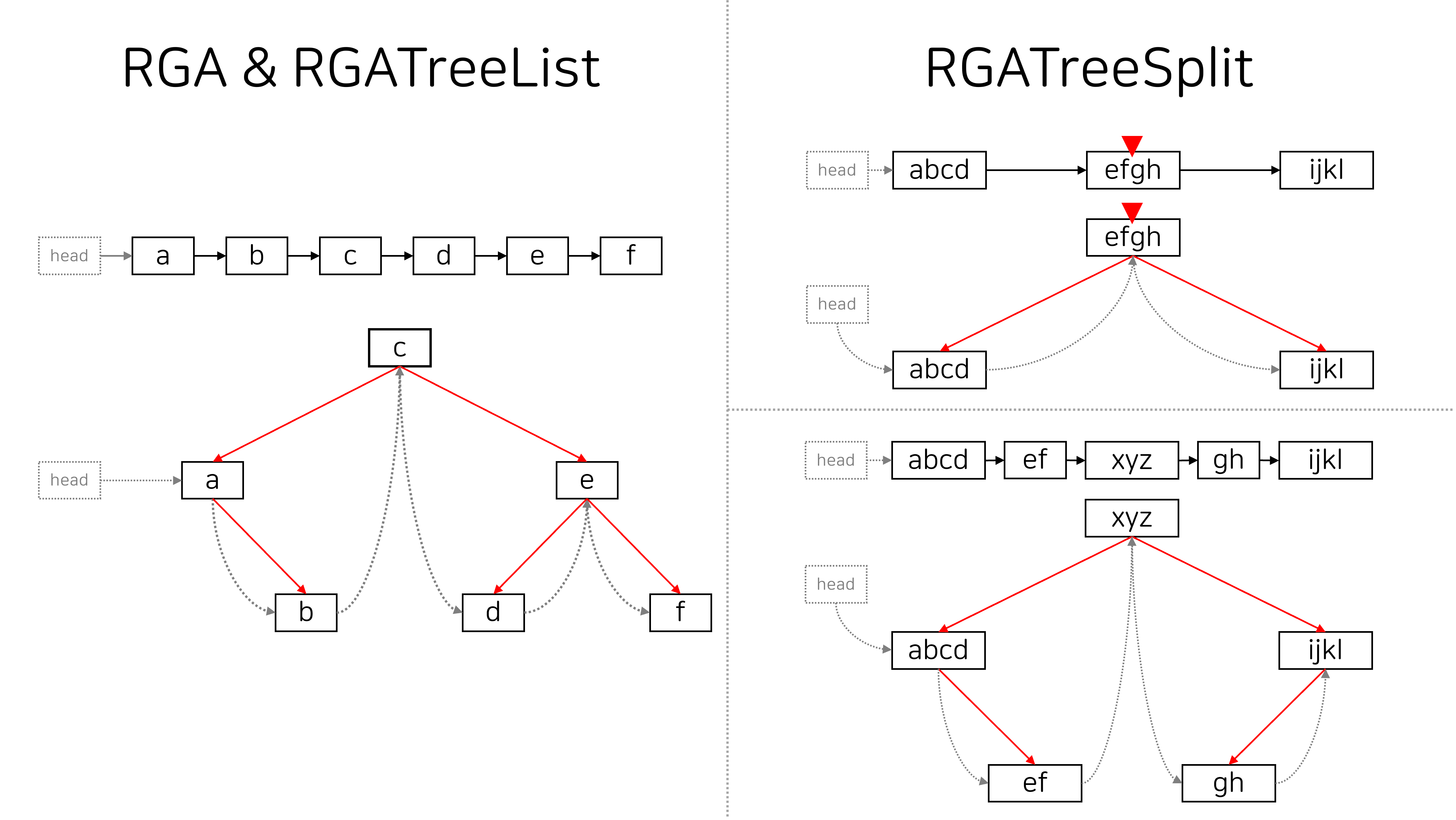
RGATreeList와 RGATreeSplit은 Replicated Growable Array(RGA)를 기반으로 하는 리스트 자료구조입니다. RGA는 기본적으로 각 노드의 크기가 1인 연결 리스트이며, RGATreeList는 random access를 지원하기 위해 os-select 연산을 수행하는 BBST 위에 리스트를 올린 자료구조입니다. RGATreeSplit은 RGATreeList의 성능을 개선하기 위해 각 노드의 크기가 1을 초과할 수 있도록 허용한 자료구조입니다. 노드의 split 연산을 지원하며, split할 인덱스가 주어졌을 때 실제로 분할될 노드를 구해야 하므로 lower bound 연산을 지원하는 BBST가 필요합니다.
SplayTree는 가장 마지막에 접근한 정점을 맨 위로 올리는 방식(splay)의 이진 탐색 트리로, 주로 같은 위치에서 연산을 여러 번 수행하는 문자열을 관리하기에 적합한 자료구조입니다. 연산 한 번에 최대 $O(n)$ 시간이 걸릴 수 있지만, $m$번 연산을 수행할 때 항상 $O((n+m) \log n)$ 시간, 즉 단일 연산의 시간 복잡도가 amortized $O(\log n)$이기 때문에 평균적으로는 빠르게 동작합니다. 또한, 후술하겠지만 Dynamic optimality conjecture 등 splay tree에 대한 여러 정리와 추측을 통해 일반적으로 꽤 빠른 자료구조라는 것이 알려져 있습니다.
LLRBTree는 일반적으로 다른 BBST에 비해 우수한 성능을 보여주는 red-black tree를 조금 변형한 자료구조로, rb tree에 디해 상대적으로 구현이 쉽다는 장점이 있습니다. LLRBTree는 SplayTree와 다르게 모든 연산을 매번 최대 $O(\log n)$ 시간에 수행한다는 장점이 있습니다.
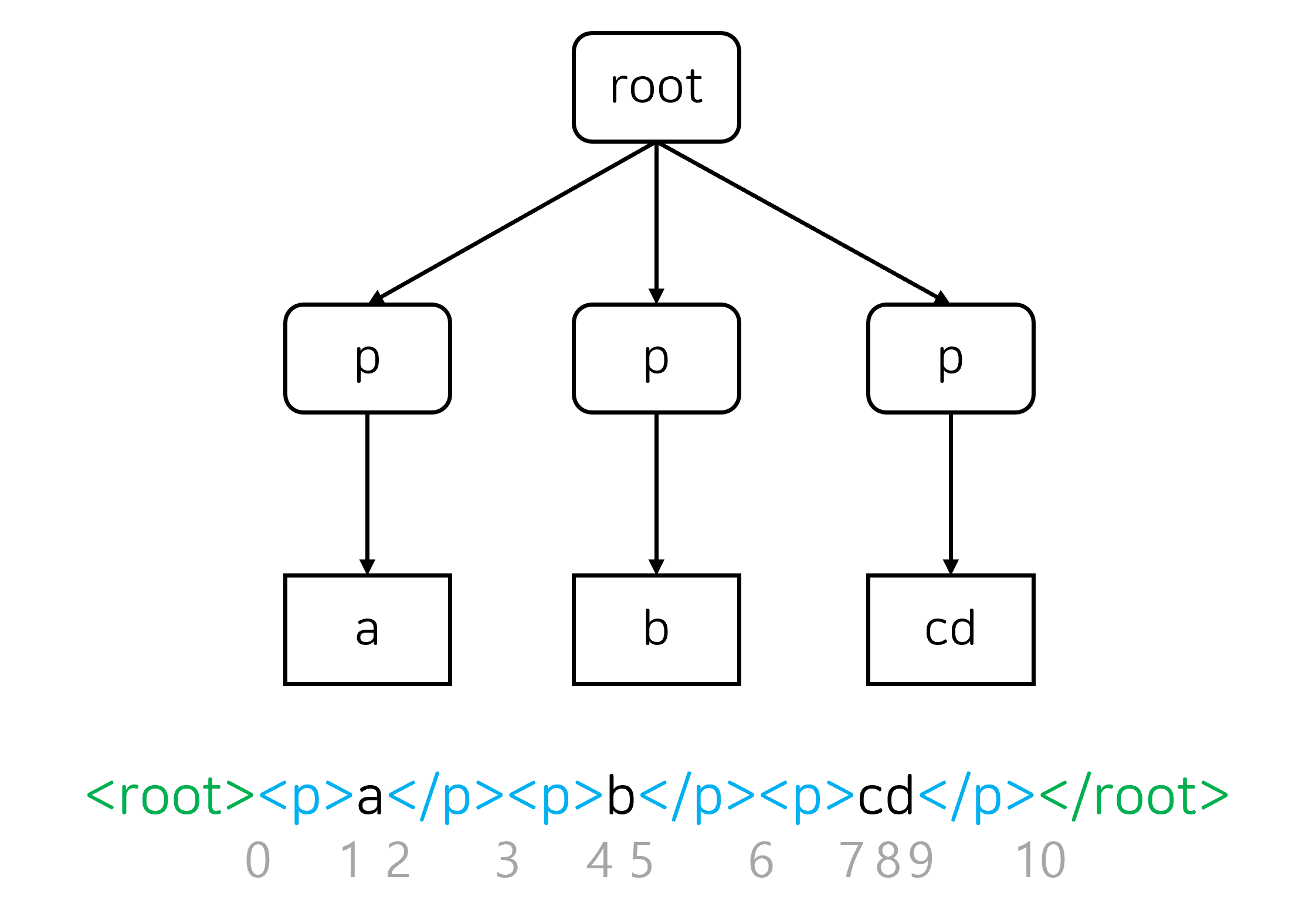
IndexTree는 xml 형태로 표현된 트리 구조 문서의 인덱스가 주어지면 이를 트리에서의 위치로 변환하는 역할을 수행합니다. 예를 들어 아래 그림에서 6번 인덱스를 넘겨주면 문서의 두 번째 p 태그와 세 번째 p 태그 사이를 “잘 표현하는 방법”을 구성해서 반환합니다.
고쳐야 할 문제
저는 8주 간의 인턴십 기간 동안 Yorkie 자료구조의 문제점을 발견하고 이를 수정하는 작업을 주로 수행했습니다. 제가 발견한 문제점은 다음과 같습니다.
- JSON-Like data structure - Tree: 동시 편집 테스트 부족함
- CRDT data structure - RHT: 동시 편집 지원 안 됨
- CRDT data structure - ElementRHT: 관리하는 자료의 타입을 제외하면 RHT와 완전히 동일한 자료구조이므로 코드 중복
- Common data structure - SplayTree: 연산 한 번의 레이턴시가 클 수 있음
- Common data structure - LLRBTree: 더 좋은 방법이 있지 않을까?
- (js-sdk) CRDT data structure - CRDTTree: garbage collector가 지수 시간 - $O(2^n)$ 시간에 동작함
RHT 동시 편집 지원
두 명의 유저가 동시에 같은 키에 대해 한 명은 삽입 연산, 다른 한 명은 삭제할 때 두 유저에게 보이는 결과가 달라지는 문제가 발생했습니다. 구체적으로 다음과 같은 시나리오에서 문제가 발생했습니다. 아래 설명에서 나오는 1@A, 2@B와 같은 문자열은 lamport timestamp에 ActorID를 추가한 것으로, 같은 원소를 수정하는 연산이 동시에 여러 개 주어지면 이벤트 발생 시간(lamport timestamp)가 큰 것을 수행하되, 그 시간이 같으면 ActorID가 큰 연산을 수행하도록 연산들 사이에 total order를 주기 위한 logical clock입니다.
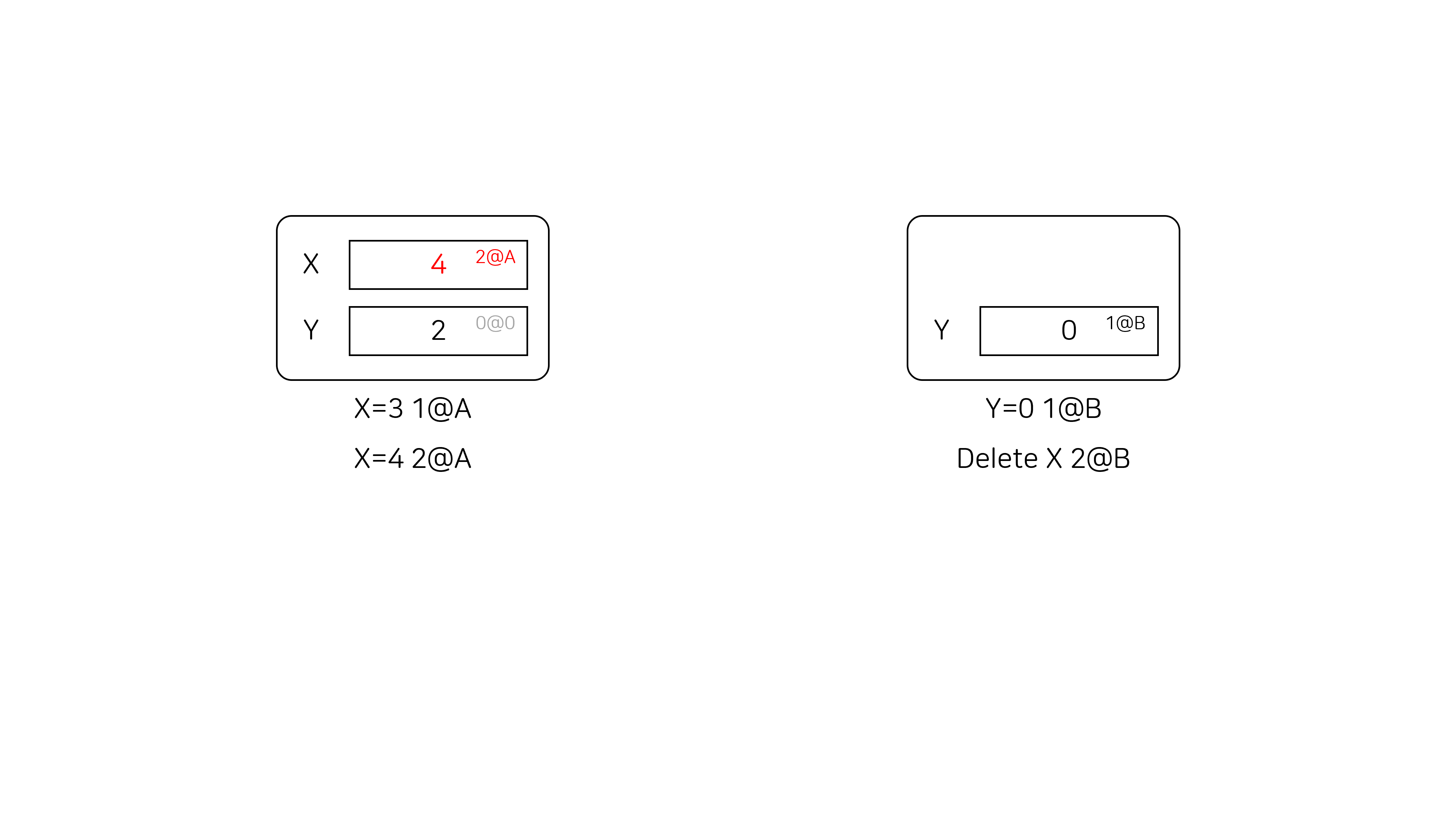
해시 테이블의 초기 상태는 {X: 1, Y: 2} 일 때, 첫 번째 유저가 X=3 1@A, X=4 2@A 라는 연산을, 두 번째 유저가 Y=0 1@B, Delete X 2@B라는 연산을 수행한 상태를 생각해 봅시다. 아직까지는 서로 동기화 작업을 수행하지 않은 상태입니다.
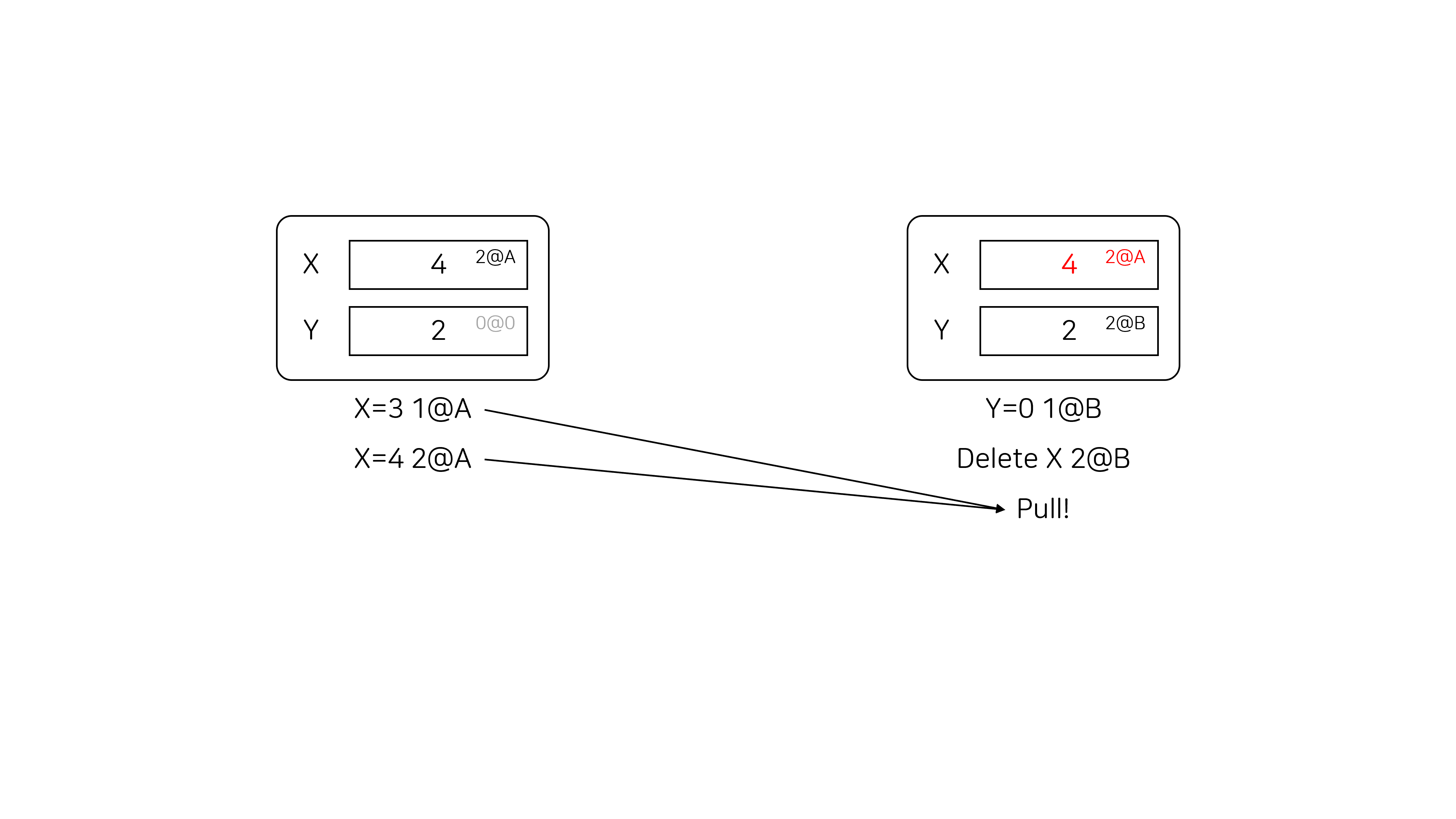
두 번째 유저가 첫 번째 유저의 연산을 pull 하면 아래 그림과 같이 됩니다. 두 번째 유저는 X에 대한 정보를 갖고 있지 않고, 첫 번째 유저는 2@A 시간에 X=4 연산을 수행했기 때문에 X의 값이 4로 변경됩니다.
이후 첫 번째 유저가 두 번째 유저의 연산을 pull 하면 아래 그림과 같이 됩니다. 첫 번째 유저의 입장에서 Y의 마지막 갱신 시간은 0@0이었는데, 두 번째 유저가 1@B 시간에 Y=0 연산을 수행했으므로 Y의 값이 0으로 변경됩니다. 또한, 첫 번째 유저의 입장에서 X의 마지막 갱신 시간은 2@A였는데, 두 번째 유저가 그보다 더 이후인 2@B 시간에 X를 삭제했으므로 첫 번째 유저의 RHT에서 X가 삭제됩니다.
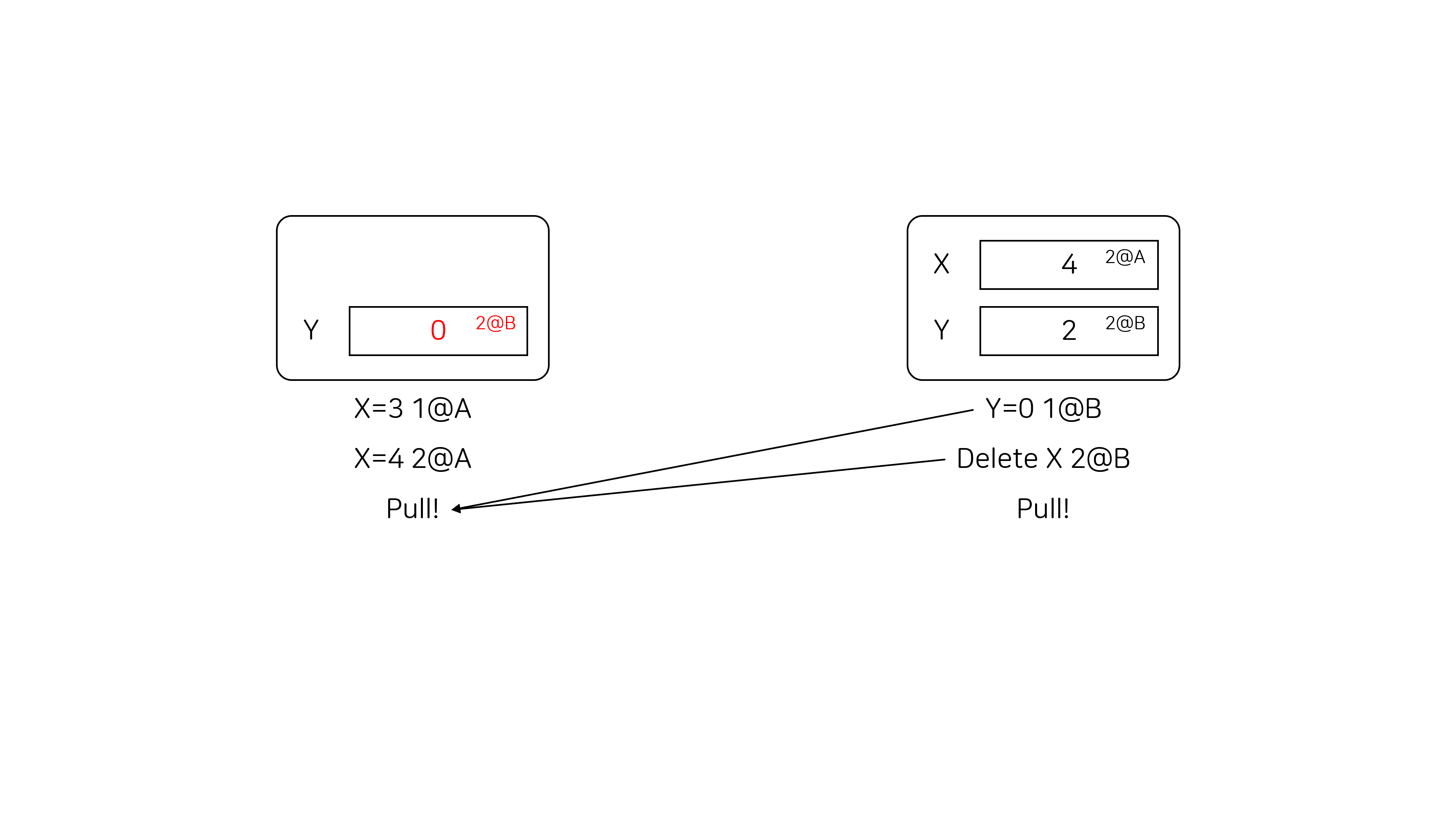
이렇게 두 클라이언트의 결과가 다르다는 문제점이 발생했고, 제거된 노드의 정보를 소멸시킨 것이 원인이었습니다. 따라서 노드를 제거할 때 정보를 완전히 삭제하는 대신, “removed” 태그만 달아놓고 실제로 삭제하지 않는 방법으로 문제를 해결할 수 있습니다. 실제로 노드를 삭제하는 것은 모든 클라이언트에 삭제 연산이 전파되었을 때 garbage collection을 수행해서 tombstone node를 제거하면 됩니다. 이 해결책을 적용하면 앞에서 본 시나리오에서 두 클라이언트의 결과가같아진다는 것을 알 수 있습니다.
두 번째 유저가 Delete X 2@B를 수행하면 실제로 X 노드를 삭제하는 대신 2@B 시점에 노드가 삭제되었다는 정보를 기록합니다.
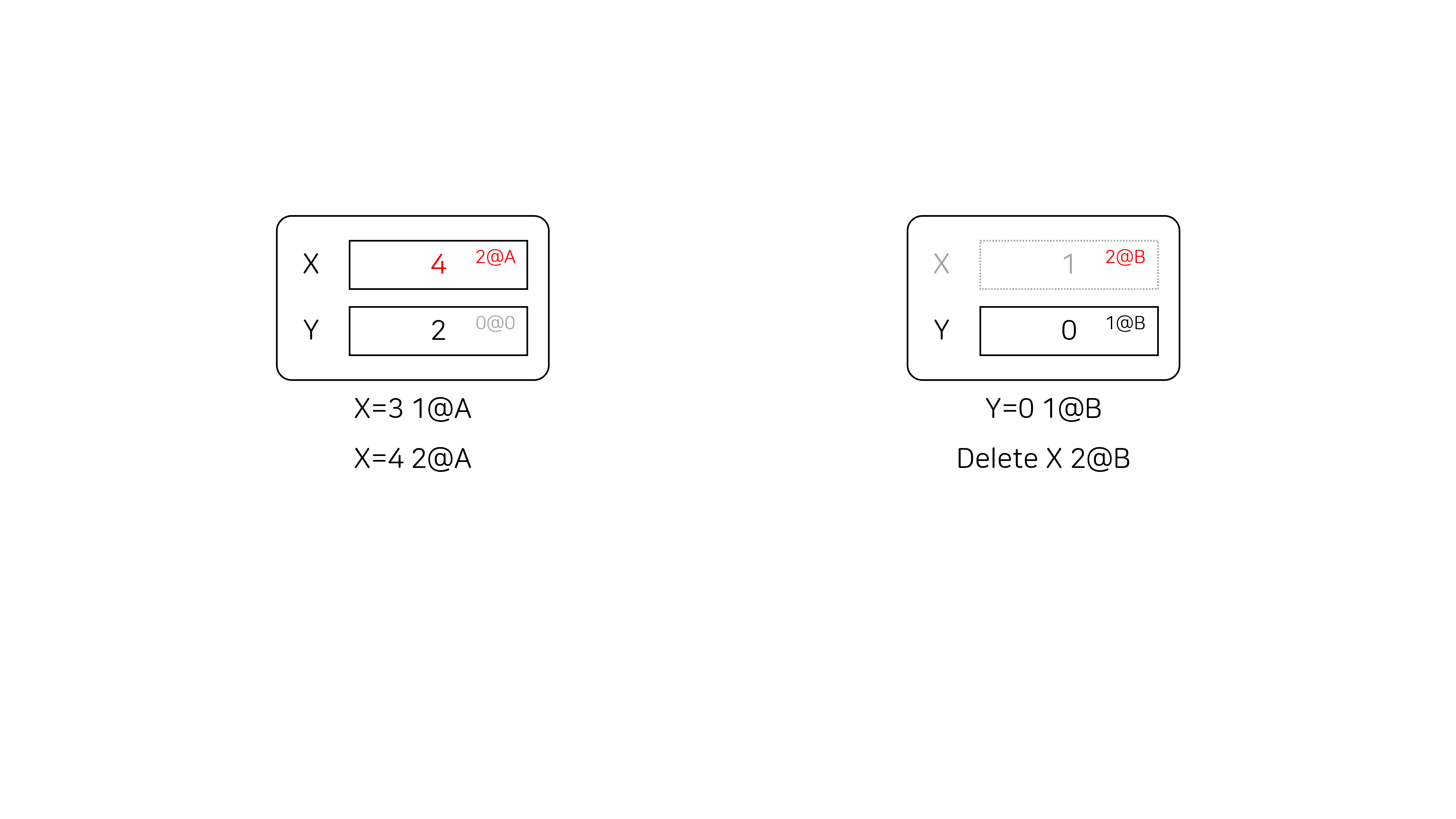
두 번째 유저가 첫 번째 유저의 연산을 pull 하면 아래 그림과 같이 됩니다. 첫 번째 유저가 X를 수정한 시점(1@A, 2@A)이 모두 2@B 이전이므로 X의 정보를 변경하지 않습니다.
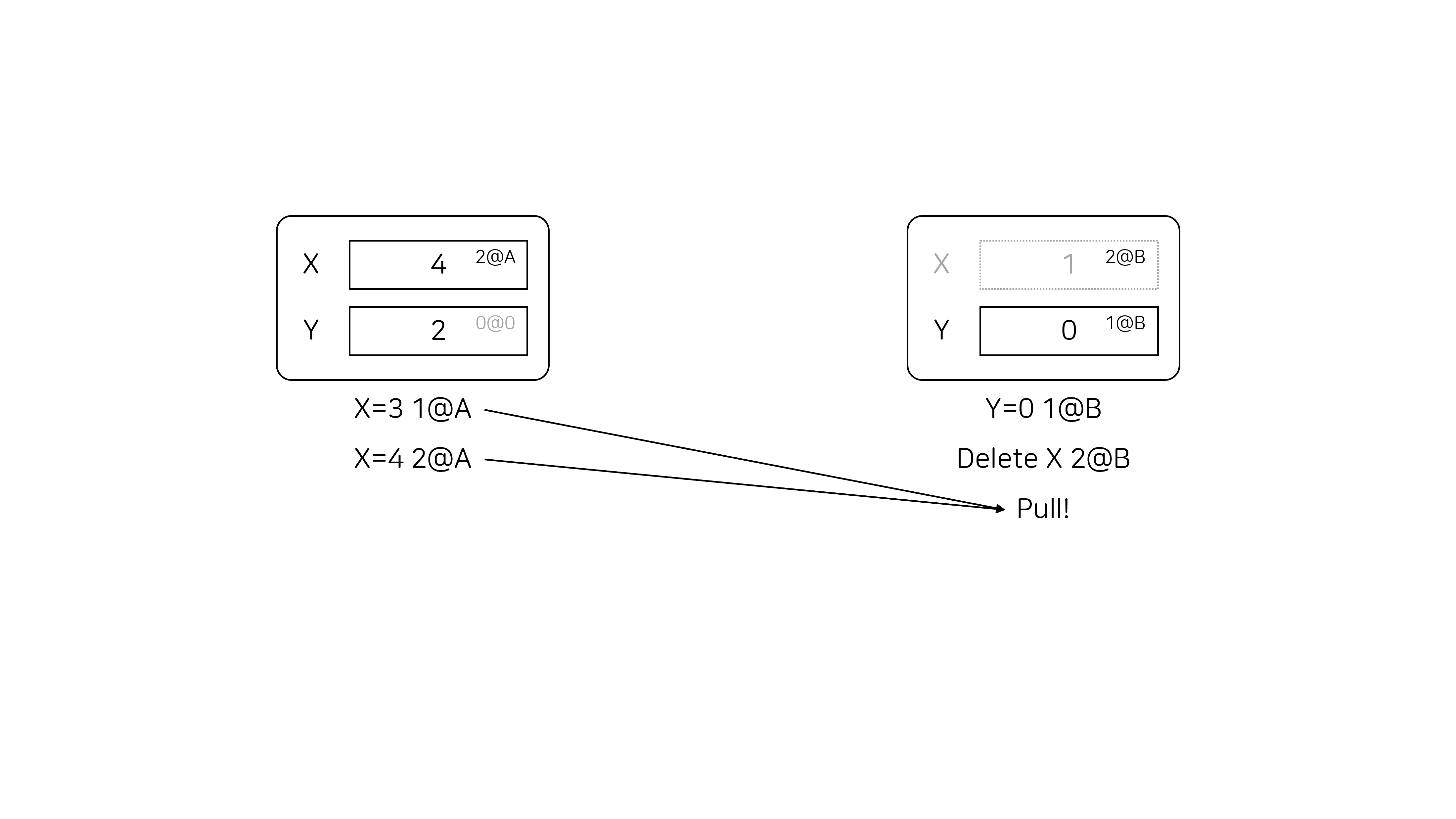
첫 번째 유저가 두 번째 유저의 연산을 pull 하면 아래 그림과 같이 두 클라이언트의 해시 테이블이 같아지는 것을 알 수 있습니다.
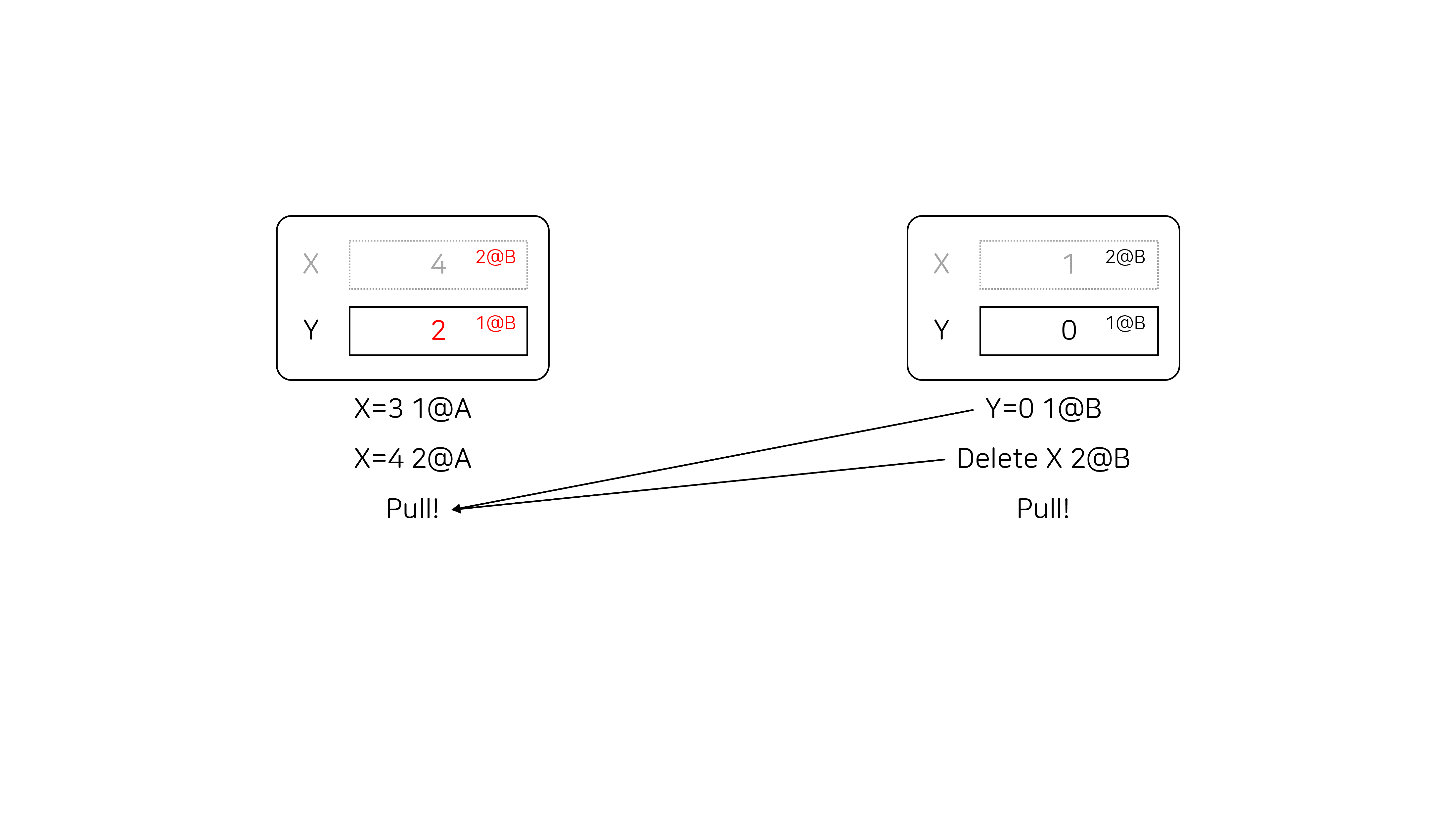
Table Driven Test 도입
기존 RHT 테스트 코드는 아래와 같이 테스트 시나리오의 각 스텝을 모두 하드코딩 하는 방식이었습니다. 이런 식으로 코드를 작성하다 보니 중복된 코드가 많아지고 읽기 어려워져서, 읽기 쉽고 일반화된 코드 스타일의 필요성을 느꼈습니다.
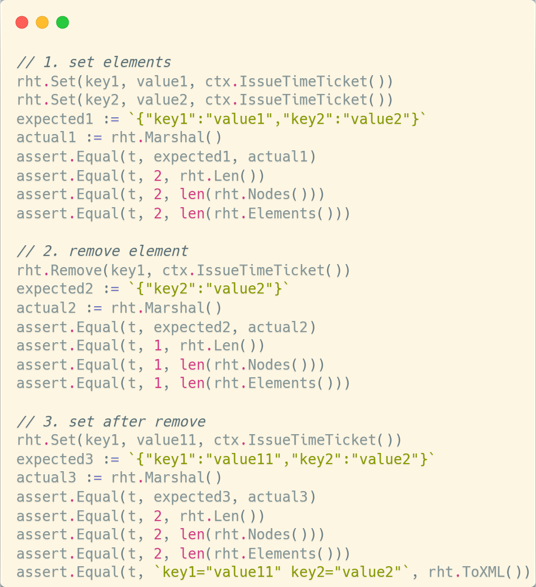
table driven test는 테스트 케이스를 테이블 형태로 정리해서 작성하는 방식입니다. 아래의 두 코드는 모두 Add(a, b)를 테스트하는 코드로, 왼쪽에 있는 코드는 모든 테스트 케이스에서의 동작을 하드코딩하는 방식, 오른쪽에 있는 코드는 테스트 케이스 설명과 기대하는 결과, 그리고 a b의 값을 테이블 형태로 작성하는 방식입니다. 테스트 케이스가 많아질수록 오른쪽의 방식이 더 읽기 쉽고 코드의 중복도 감소한다는 것을 알 수 있습니다.

아래 코드처럼 외부 변수를 사용하면 context를 유지하면서 여러 시나리오를 차례대로 수행할 수도 있습니다. 아래 코드는 sum의 값을 0으로 초기화한 뒤, 차례대로 값을 더해가면서 값의 변화를 확인하는 방식의 테스트 코드입니다.

rht_test.go에서 table driven test 형식으로 작성한 RHT의 테스트 코드를 확인할 수 있습니다.
Garbage collector 수정
Yorkie는 위에서 언급한 tombstone node를 제거하기 위한 garbage collector(design docs)를 갖고 있습니다. garbage collection의 대략적인 과정은 다음과 같습니다.
registerRemovedElement(element)를 이용해 tombstone node 등록(removedElementSetByCreatedAt에 삽입)- 적절한 시기에 호출된
garbageCollect(timestamp)에서timestamp시점 이전에 등록된 모든 tombstone node에 대해deregisterElement(element)호출 deregisterElement(element)는 언어에서 제공하는 GC가element를 제거할 수 있는 형태로 전환
Yorkie의 garbage collector는 두 가지 문제가 있었는데, 첫 번째 문제는 등록된 garbage의 개수를 구하는 getGarbageLen() 함수가 올바르지 않은 값을 반환하는 것(관련 이슈, PR), 두 번째 문제는 deregisterElement에서 같은 원소를 여러 번(무려 최대 $O(2^n)$번!, 관련 이슈, PR) 제거하는 것이었습니다.
getGarbageLen() 이슈는 nested object에서 조상-자손 관계인 두 정점 $p, c$가 모두 tombstone node로 등록된 경우에 $c$와 $c$의 자식들을 중복해서 카운팅하는 것이 원인이었고, 다른 분께서 set을 이용해 중복을 제거하는 방법을 이용해 해결하셨습니다(commit).
하지만 이 솔루션은 skew tree와 같은 형태에서 모든 노드가 tombstone node로 등록되어 있을 때 $O(n^2)$ 시간이 걸립니다. 따라서 저는 tombstone node를 정렬해서 위에 있는 노드부터 삭제하는 방식의 $O(n \log n)$ 방법을 만들어 내고, 성능 개선 확인을 위한 테스트 코드를 작성했습니다. skew tree에서 테스트를 돌렸는데 성능 변화가 없어서 무슨 일인지 확인을 했더니… 10개의 정점으로 구성된 트리를 삭제할 때 garbage collector에서 522개의 정점을 deregister하고 있었습니다. 정점이 9개인 트리를 삭제할 때는 265개의 정점을, 정점이 11개인 트리를 삭제할 때는 1035개의 정점을 deregister하고 있었습니다. 테스트 코드에서는 garbage의 개수와 실제 garbage collecting 과정에서 deregister된 원소의 개수를 함께 세고 있었는데, deregisterElement가 터무니없이 많이 호출되고 있어서 성능 변화가 눈에 보이지 않고 있었던 것이었습니다.
$f(9) = 265, f(10) = 522, f(11) = 1035, \ldots$ 수가 너무 익숙합니다. 특히 $522$라는 수는 보자마자 $522 = 512 + 10$이 생각났고, 조금 더 고민해 보니 $f(n) = 2^{n-1} + n$이라는 것을 알게 되었습니다. 알 수 없는 이유로 deregisterElement() 안에서 원소가 지수 번 삭제되고 있었고, 저는 getGarbageLen()의 $O(n \log n)$ 구현 대신 이 문제를 해결하기로 했습니다.
기존에 deregisterElement()는 아래와 같이 구현되어 있었습니다.
1 | |
위 코드에서 6-10번째 줄만 잘라내서 deregisterElementInternal(element); 바로 아래로 옮기면?
1 | |
문제가 해결되었습니다! skew tree에서 맨 위에 있는 정점을 deregister 할 때 정점들이 총 $f(n) = 1 + \sum_{i=1}^{n-1} f(i) = 2^{n-1}$번 삭제되고 있었고, 나머지 $+n$은 그냥 테스트 코드를 잘못 짜서(…) 붙었던 것이었습니다. 아무튼 코드 한 줄 작성하지 않고 시간 복잡도를 $O(2^n)$에서 $O(n)$으로 줄이는 재미있는 경험을 했습니다.
여담으로, 결국 getGarbageLen()의 $O(n \log n)$ 구현은 Yorkie에 반영되지 않았습니다. 글 작성하면서 $265, 522, 1035$를 oeis(온라인 정수열 사전, https://oeis.org)에 넣었더니 $a(n) = 2^n + n + 1$이라는 수열(A005126)이 나왔습니다. 이럴 줄 알았으면 열심히 고민해서 식 때려 맞추지 말고 oeis에 넣어볼걸…
Tree 연산 소개
Yorkie에서 트리 구조의 문서를 담당하는 Tree는 다양한 연산을 제공합니다. Tree의 연산은 크게 basic edit, advanced edit, style 로 구분할 수 있습니다.
- Basic tree edit: Insert, Delete, Replace
- Advanced tree edit: Split, Merge
- Style: Style, RemoveStyle
Insert는 원하는 위치에 새로운 노드를 삽입하는 연산, Delete는 삭제하고 싶은 노드의 양쪽 끝 인덱스를 넘겨서 노드를 삭제하는 연산, Replace는 Delete와 Insert를 조합해서 노드를 교체하는 연산입니다.
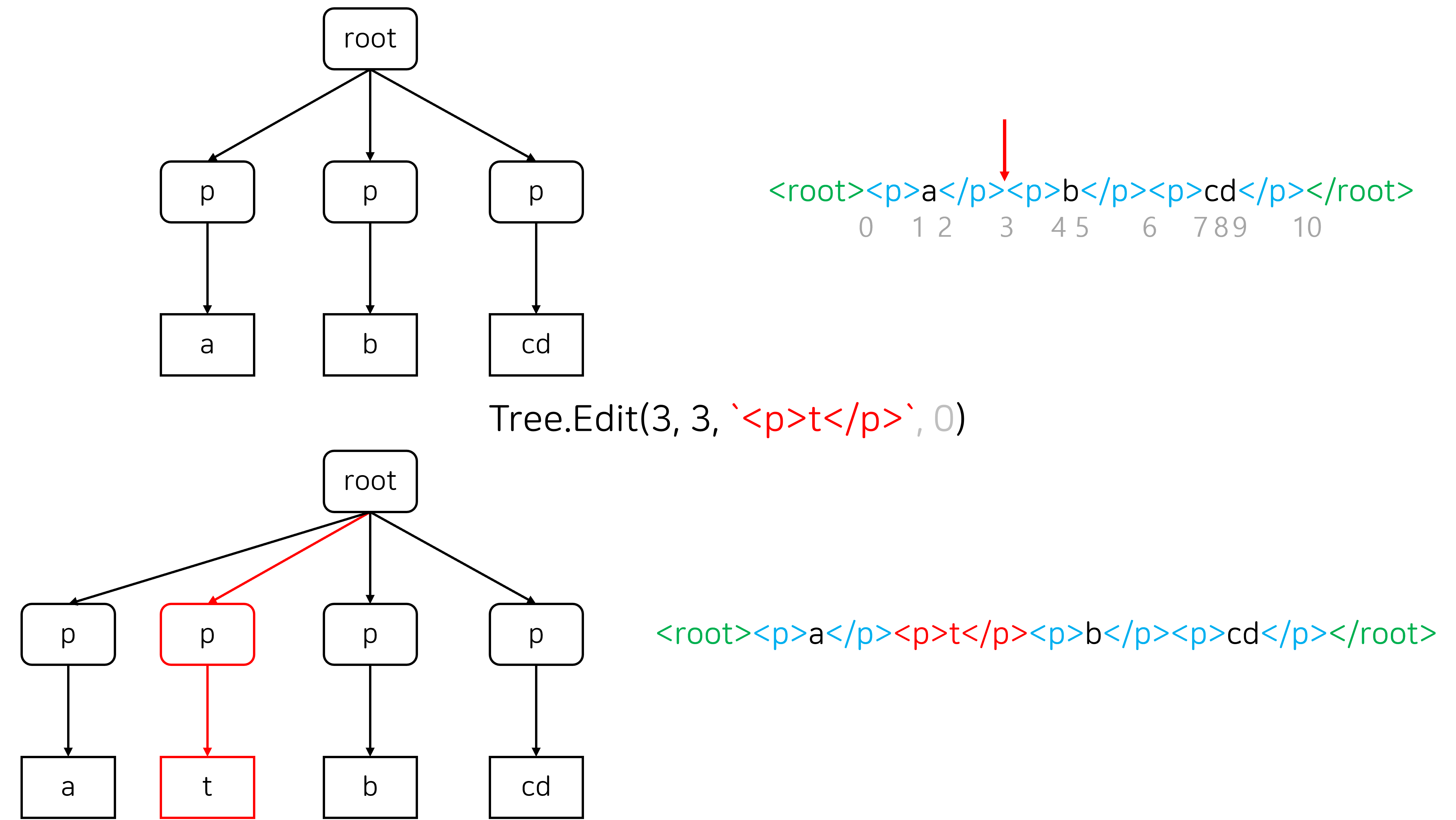
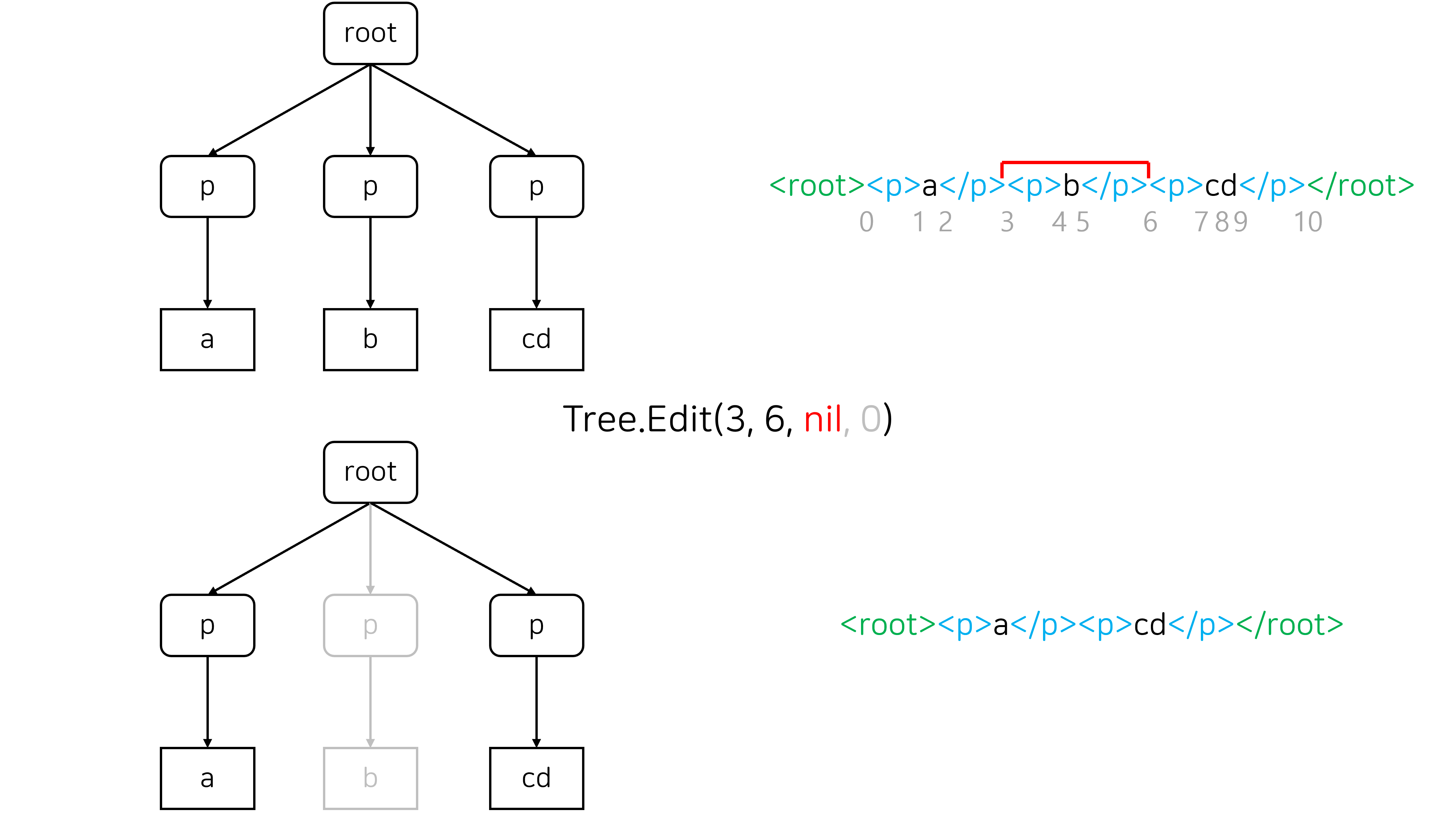
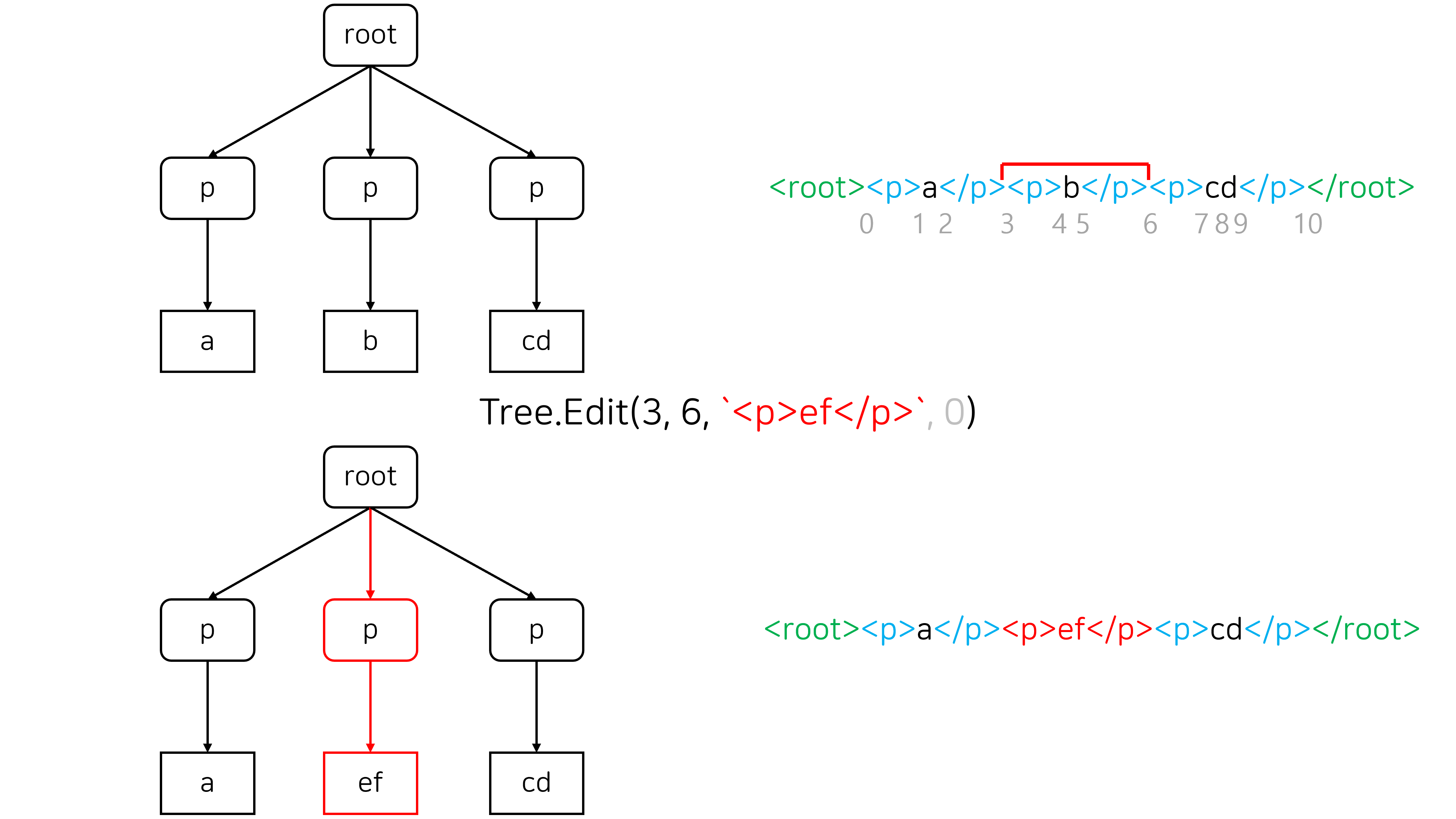
Merge는 두 노드를 병합하는 연산입니다. 주로 두 번째 그림과 같이 양 끝점이 서로 다른 block element에 속한 구간을 선택해서 삭제할 때 발생합니다.
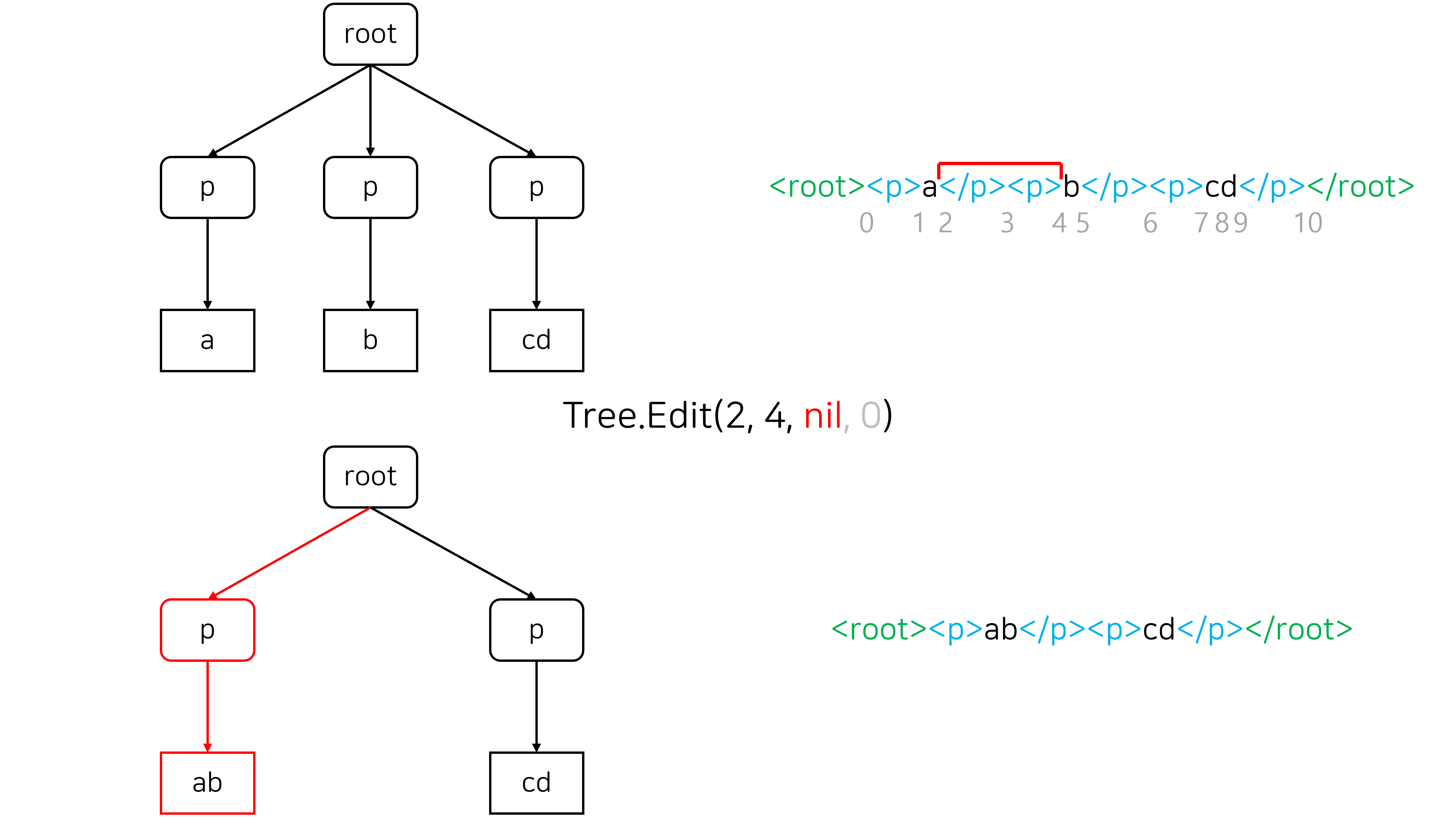
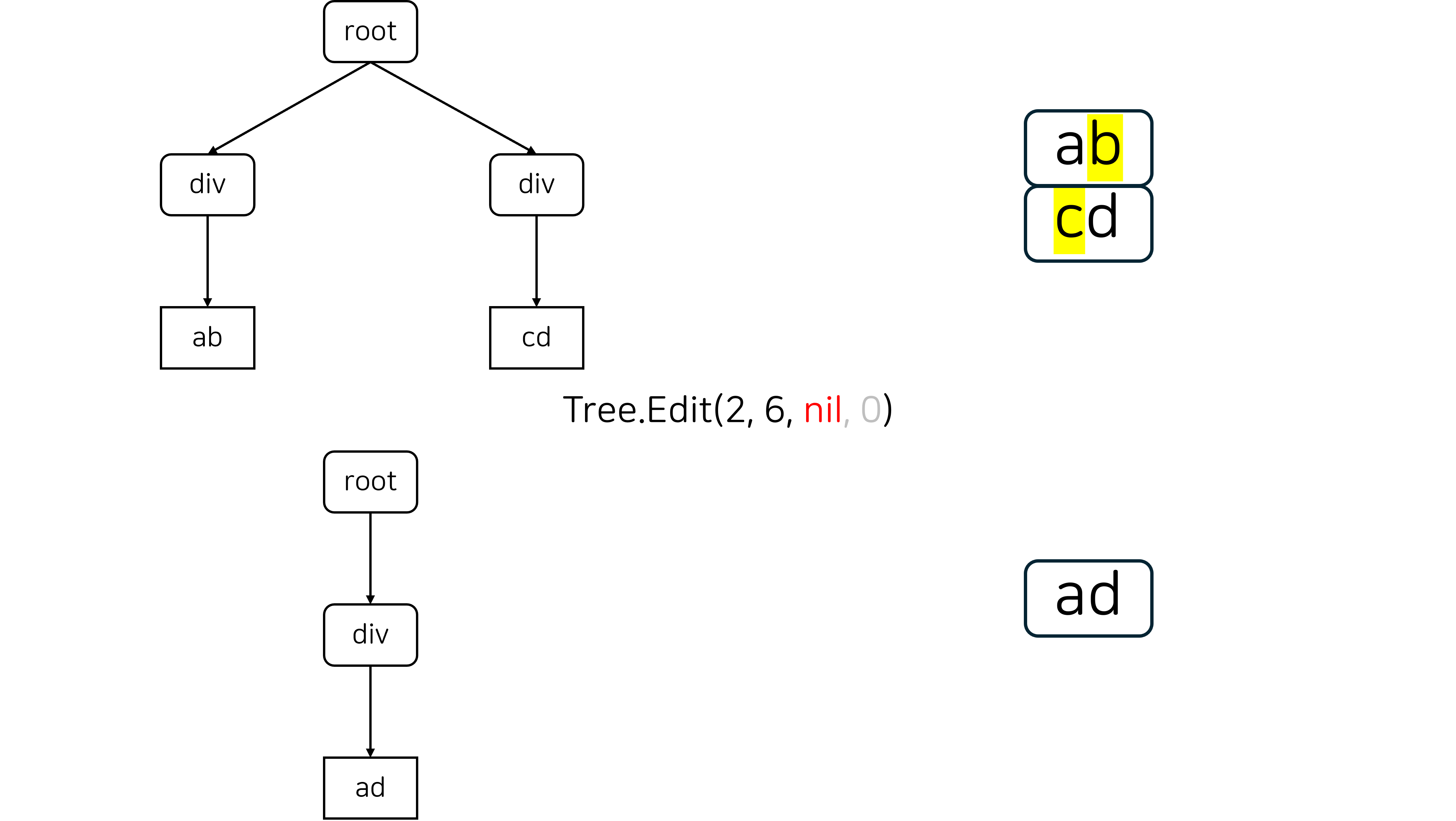
Tree.Edit의 4번째 인자는 splitLevel로, split 연산을 수행할 때 몇 번째 조상 정점에서 분할할 지를 결정하는 인자입니다. splitLevel = 1 일 때는 분할하려는 인덱스가 포함된 정점의 부모 정점을 분할하고, splitLevel = 2 일 때는 2칸 위 조상 정점을 분할합니다.
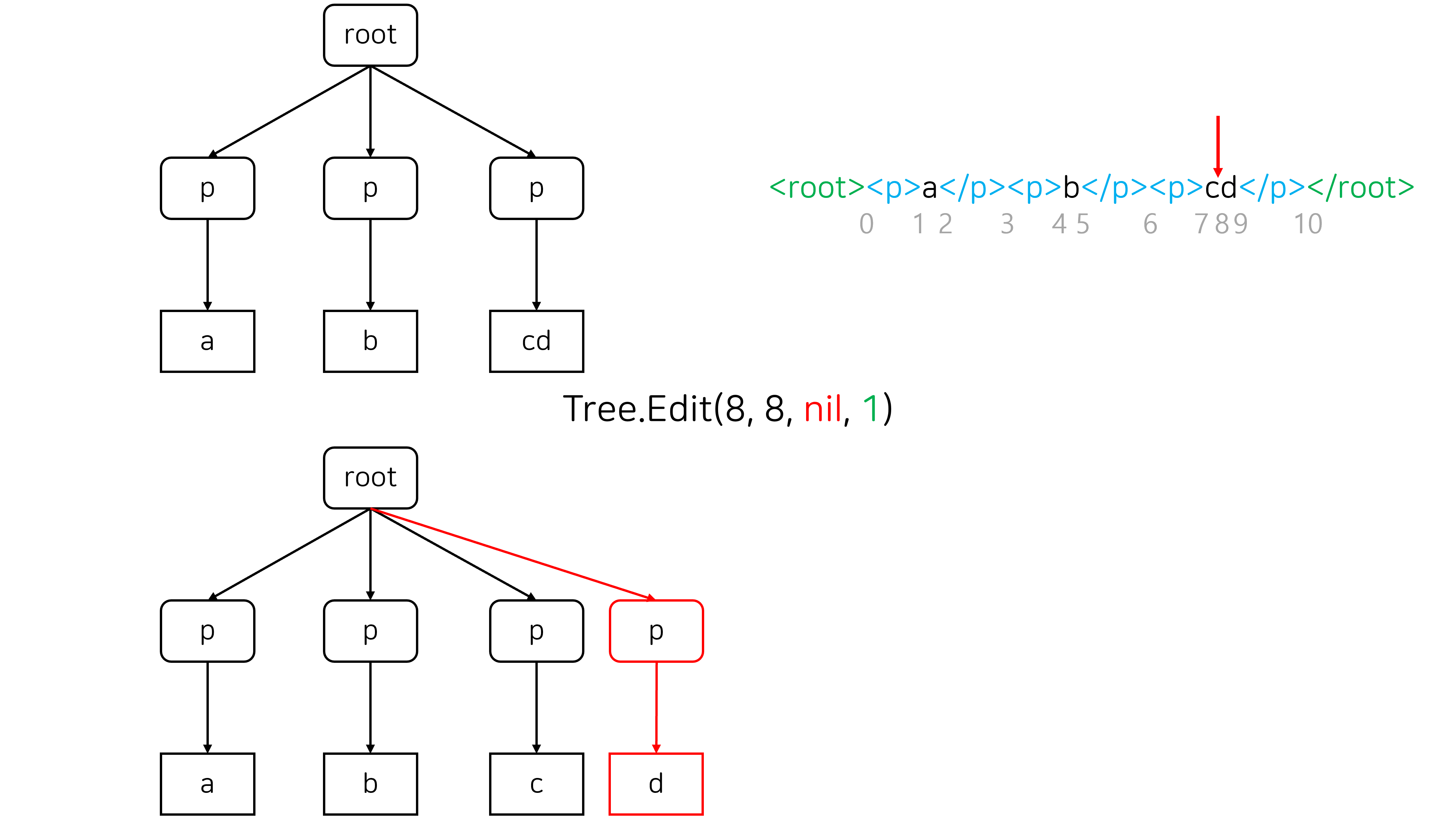
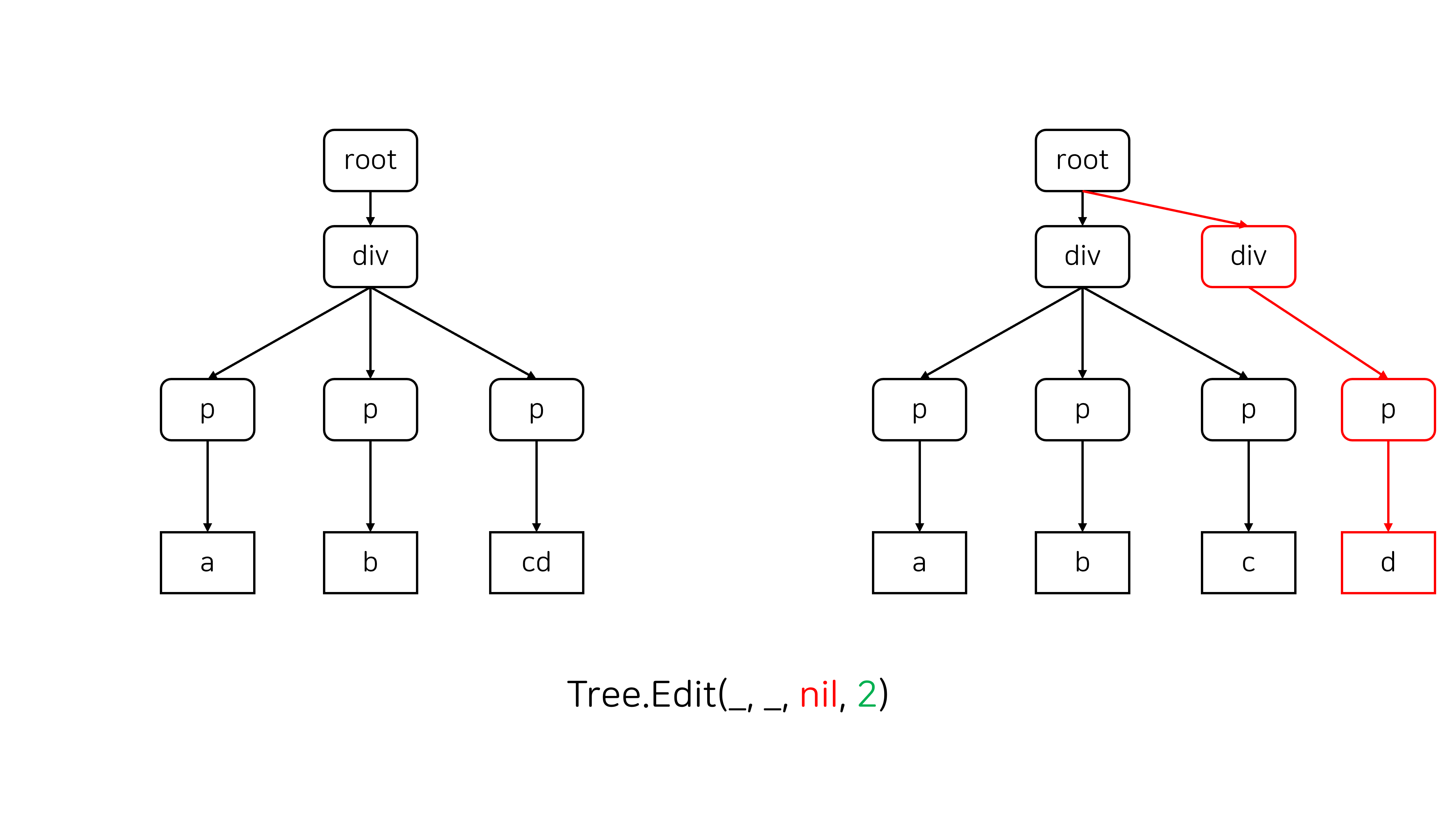
Split은 주로 어떤 노드 안에 <hr>과 같은 새로운 block element를 삽입할 때 발생합니다.
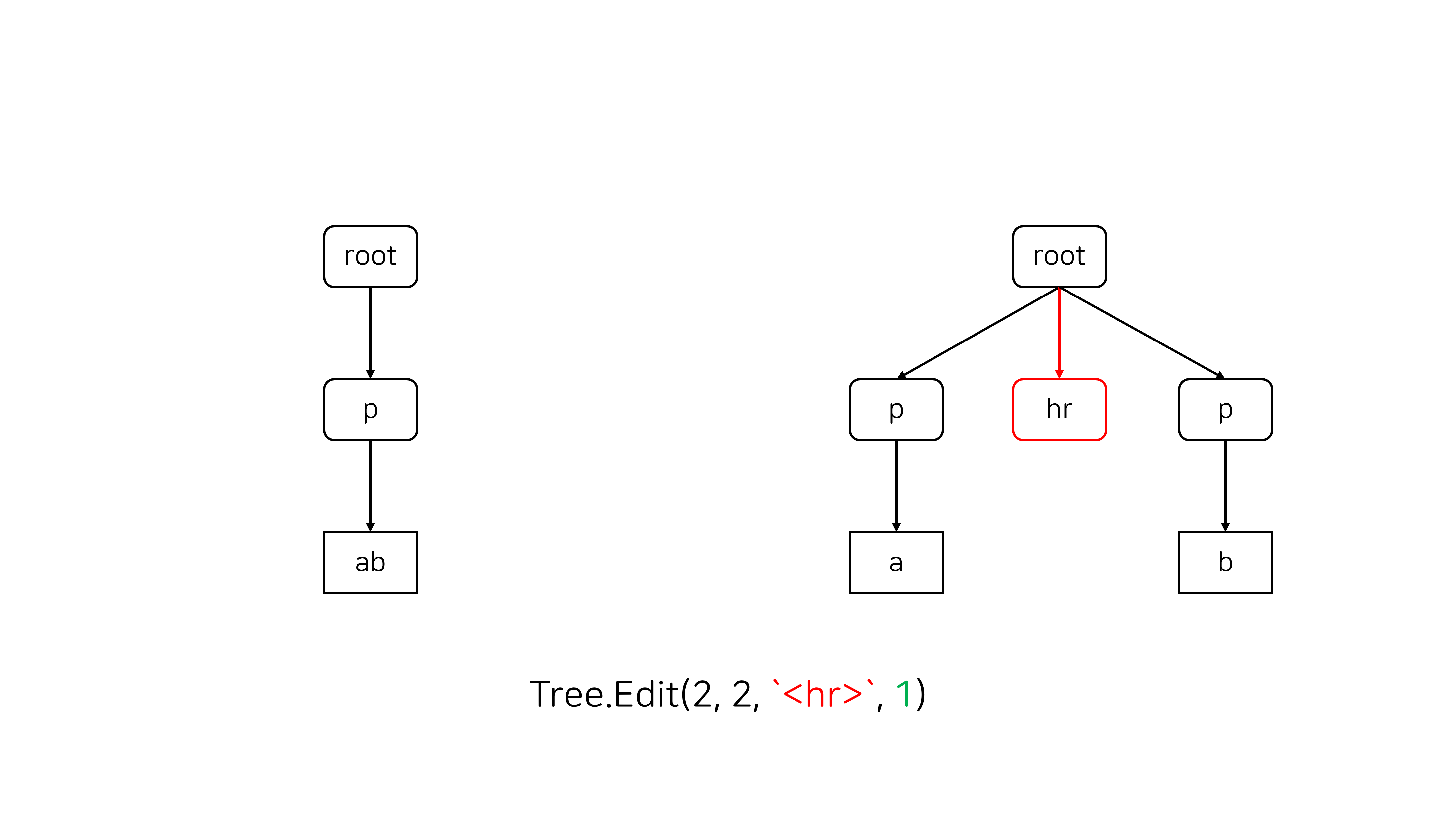
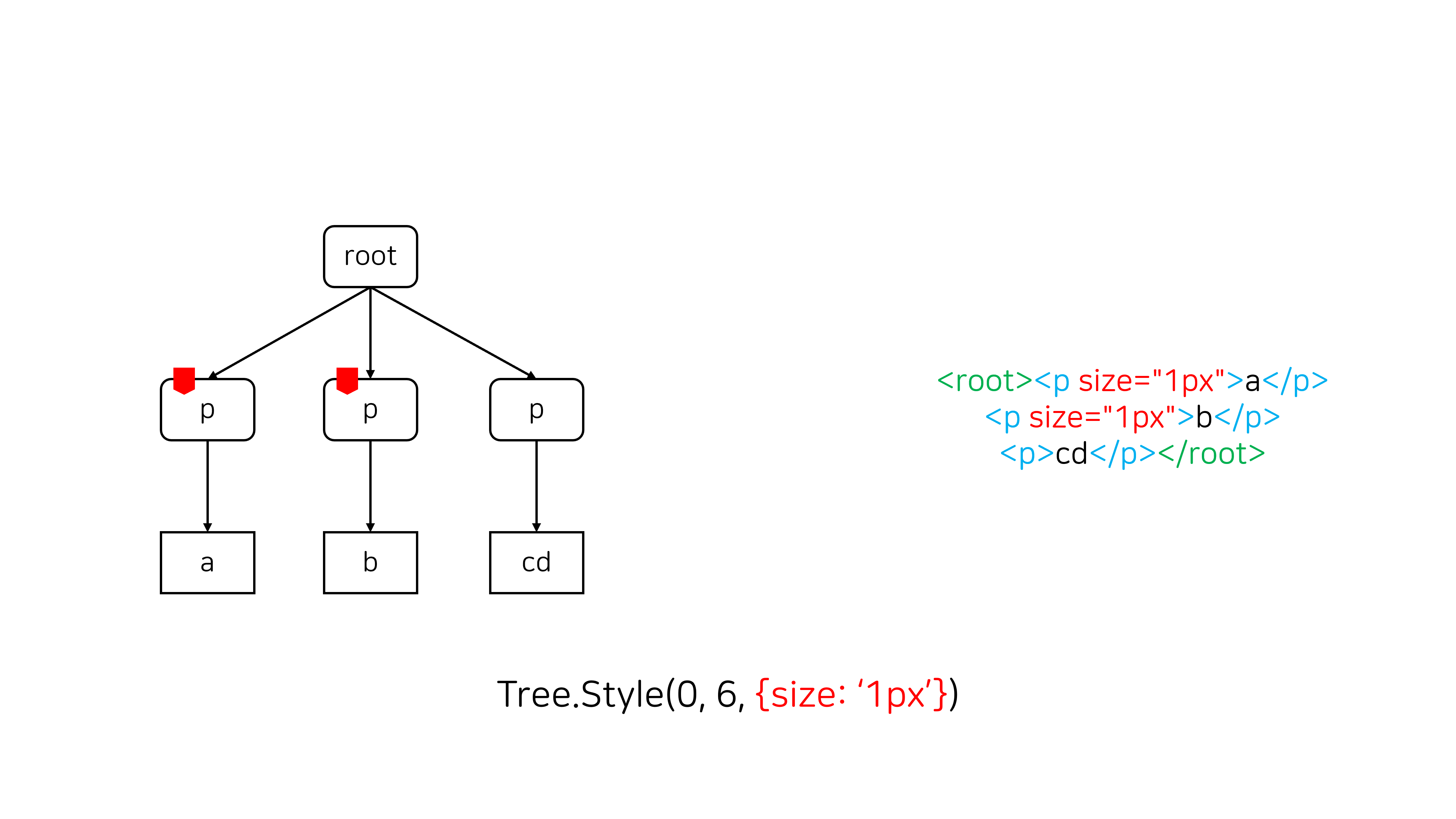
Style과 RemoveStyle은 주어진 구간에 속한 노드에 attribute를 추가/제거하는 연산입니다.
트리 동시 편집 테스트 프레임워크
기존에도 트리의 동시 편집 기능을 하는 테스트 코드가 있었습니다. 아래 그림과 같이 테스트 내용을 3개의 차원으로 분할한 뒤, 각 차원마다 3개씩 총 27가지의 대분류로 나눠서 테스트를 작성했습니다.

이런 방식의 문제점은 크게 두 가지가 있는데, advanced edit이나 style 연산에 대한 테스트 작성 가이드가 없다는 것, 그리고 아래 이미지와 같이 27가지 대분류 안에서 세부 내용을 일일이 직접 구현하고 있다는 것입니다.
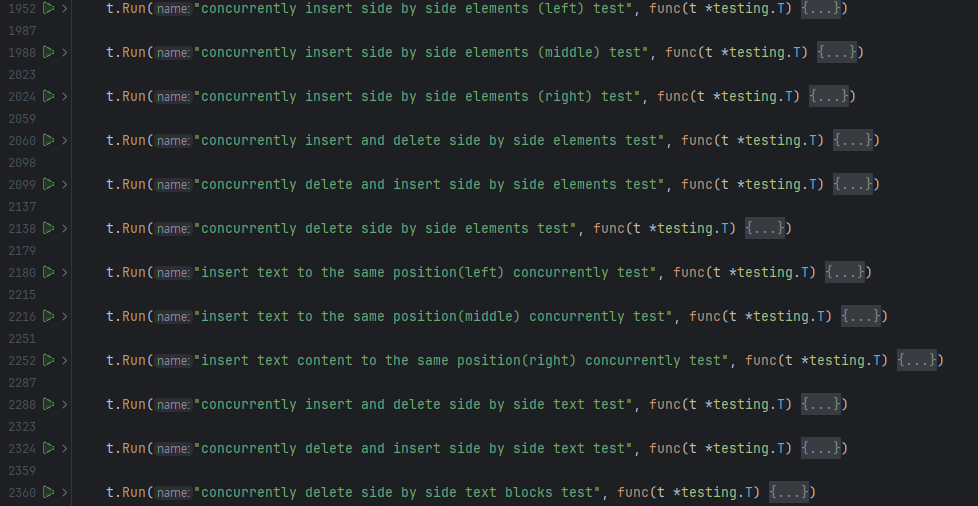
이런 식의 테스트는 테스트 커버리지를 확인하기 어려울 뿐만 아니라, 트리의 기능을 수정하거나 새로운 기능을 추가할 때마다 여러 개의 테스트 코드를 다시 수정해야 한다는 문제점이 있습니다. 더 나아가, 현재 테스트 코드가 발생할 수 있는 모든 동시 편집 상황을 표현한다는 보장이 없으므로, 문제를 발견할 때마다 땜질하는 느낌으로 수정하고 테스트 코드를 추가하는 것을 반복하고 있어서 언제 트리 구현이 완료될지 모르는 상황이었습니다.
따라서 새로운 동시 편집 테스트 프레임워크를 설계하기로 결정했습니다. 새로운 프레임워크의 목표는 두 가지로 설정했습니다.
- 연산의 교환 법칙 성립 여부 확인 → 연산 2개의 순서를 바꿔가며 테스트
- 실패하는 테스트를 한 눈에 볼 수 있도록 제작 + 실패하는 테스트는 Skip 처리해서 CI는 항상 통과되도록 조정
각 테스트마다 2개의 연산만 고려하면 되기 때문에 테스트는 (1) 두 유저가 구간을 선택하는 방법, (2) 첫 번째 유저의 연산, (3) 두 번째 유저의 연산까지 총 3개의 차원으로 나눠서 구분하기로 결정했습니다. 두 유저가 선택하는 구간은 기본적으로 아래 그림과 같이 4가지 정도로 나눌 수 있지만, 유저들이 사용하는 연산의 종류에 따라 더 많이 고려해야 할 수도 있습니다.
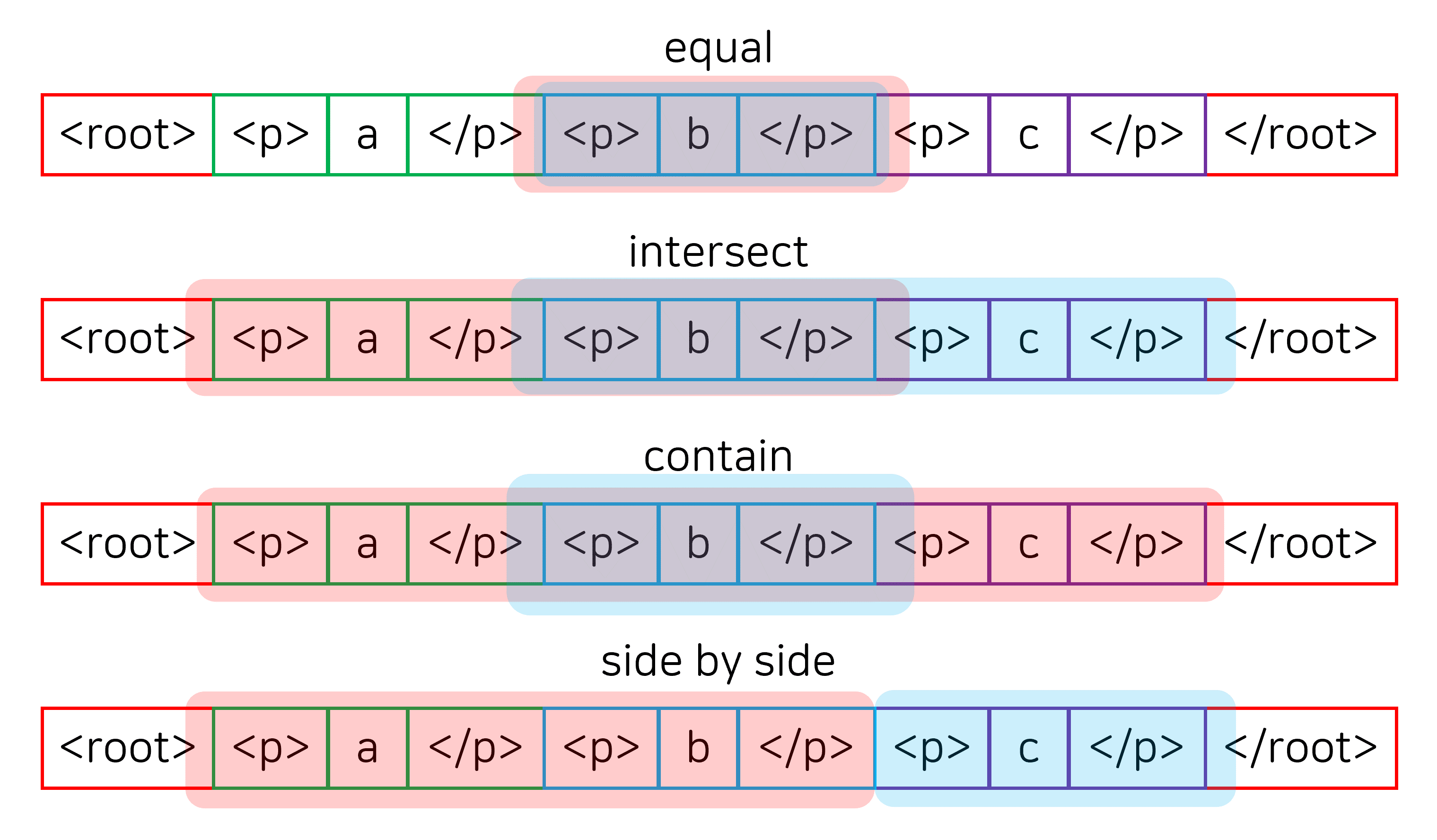
예를 들어 첫 번째 유저는 Edit 계열의 연산, 두 번째 유저는 Style 계열의 연산을 사용한다고 가정하면 A contains B와 B contains A를 모두 확인해야 합니다. 또한, Style 계열의 연산은 트리의 노드에만 적용하는 연산이므로 위 그림과 같이 구간을 설정하면 충분하지만, Edit 계열의 연산은 text node를 수정하는 것, element node를 수정하는 것, 둘 모두를 수정하는 것을 모두 확인해야 합니다.
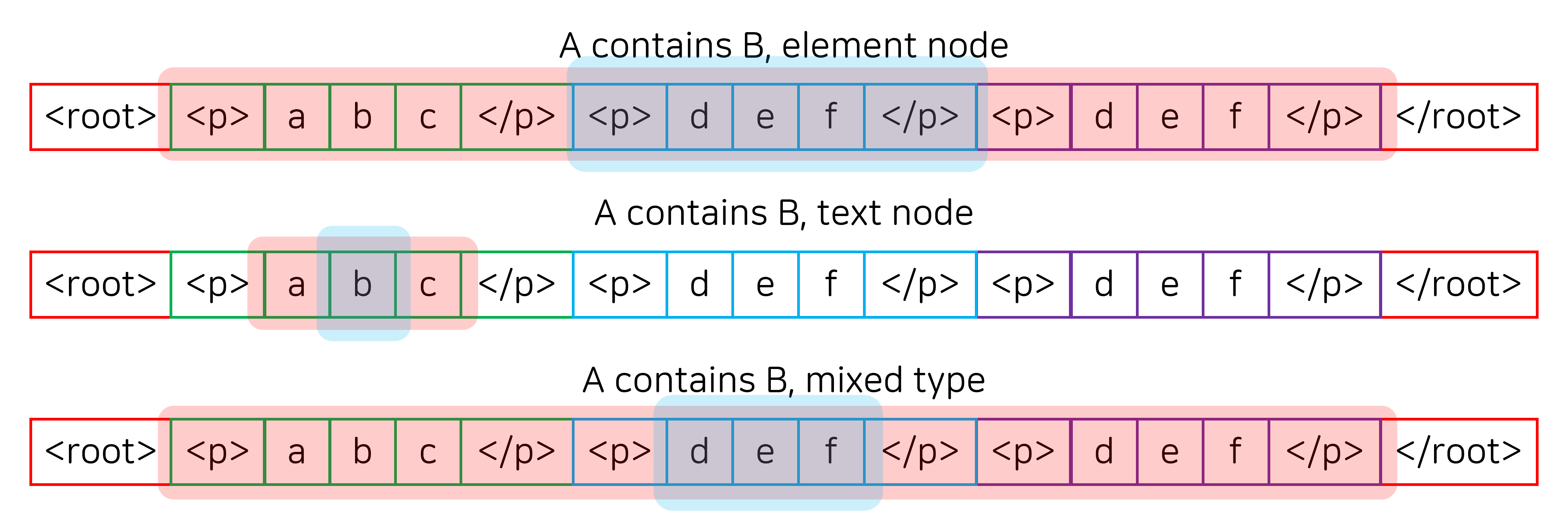
이런 식으로 테스트 상황에 따라 각 차원에 들어가는 요소들이 천차만별이기 때문에, 테스트 타입마다 각 차원에 들어갈 요소를 간편하게 지정할 수 있는 구조를 만들고자 했습니다.
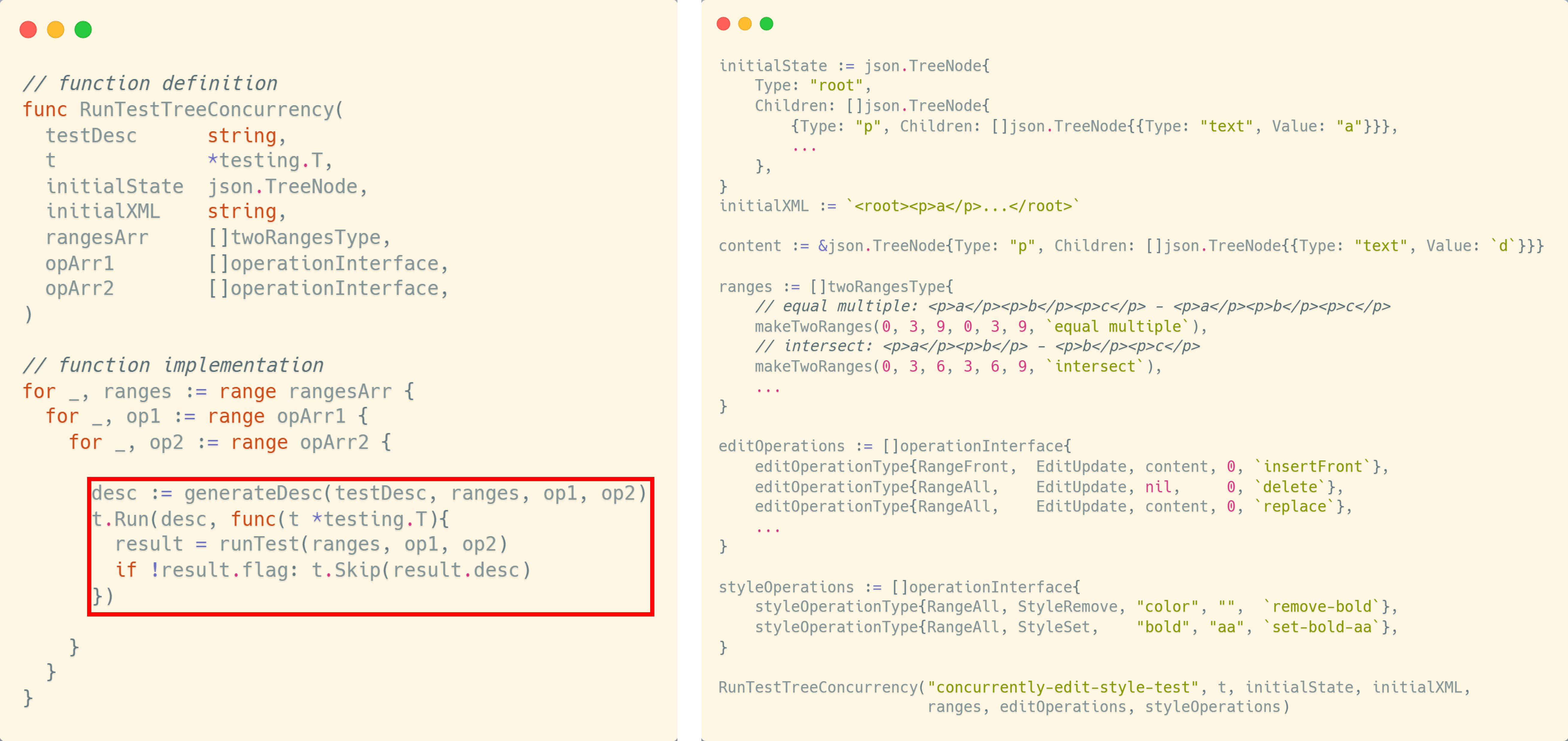
새로 작성한 테스트 프레임워크에서 테스트는 RunTestTreeConcurrency 함수를 이용해 수행할 수 있습니다. 이 함수는 테스트 전체에서 공통으로 사용될 트리의 초기 상태(initialState, initialXML)와 각 차원에 들어갈 정보(rangesArr, opArr1, opArr2)를 인자로 받은 뒤, 함수 내에서는 단순히 3중 반복문으로 모든 조합을 생성해 결과를 받아오는 방식으로 동작합니다. 오른쪽 코드와 같이 초기 상태와 각 차원에 들어갈 요소들의 배열을 선언하면 테스트를 간편하게 수행할 수 있습니다. 기존 테스트를 보강하고 싶을 때는 단순히 배열 선언 부분에 한 줄만 추가하면 됩니다.
실패하는 테스트는 Skip 처리를 했기 때문에 CI는 항상 통과됩니다. 또한, IDE의 기능을 이용하면 아래 사진과 같이 skip 된 테스트를 모아서 볼 수 있어서, 현재 프로젝트에서 커버하지 못하는 케이스 수에 대한 정량적인 분석이 가능해졌습니다.
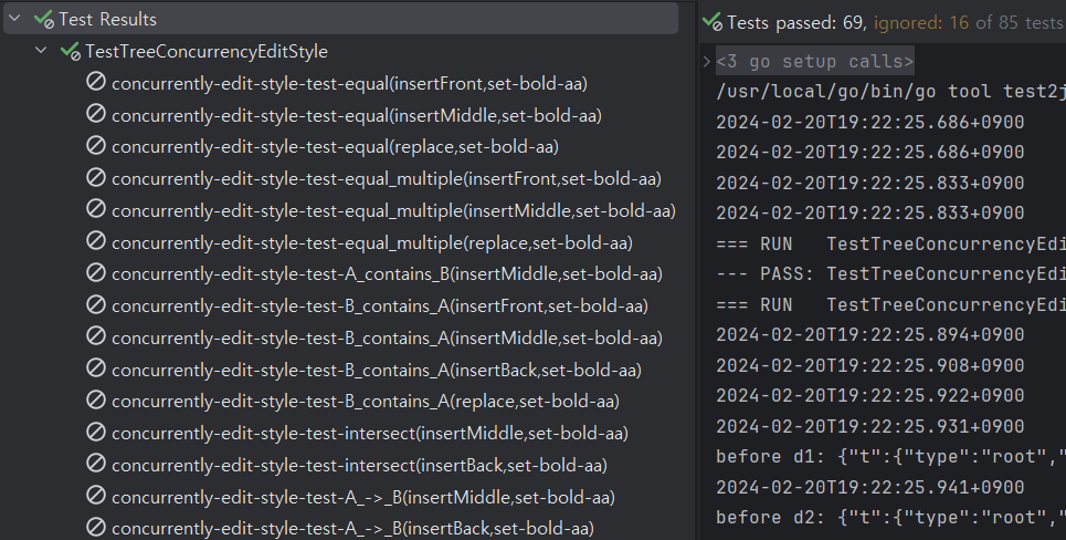
또한, 각 차원에 들어갈 요소에 이름을 붙이면 자동으로 테스트에도 이름이 붙는다는 장점도 있습니다. 이를 통해 “concurrently-edit-style-test-equal(insertFront,set-bold-aa) 에서 실패해요!”, “이 방식은 EditStyleTest 에서 실패하는 15가지 중 10가지를 커버할 수 있어요!”와 같이 실패하는 케이스를 정확하게 집을 수 있어서 개발자들 간의 소통이 조금 더 원활해졌다는 소소한 이득이 있었습니다.
새로 작성한 테스트 프레임워크는 tree_concurrency_test.go에서 확인할 수 있습니다.
이진 탐색 트리 개선 방안 제안
위에서도 언급했듯이 스플레이 트리는 연산 한 번에 최대 $O(n)$ 만큼의 시간이 필요할 수 있지만, 연산을 $m$번 수행할 때의 전체 시간 복잡도는 항상 $O((n+m) \log n)$이 보장되는 자료구조입니다. 스플레이 트리는 다음과 같은 다양한 성질이 알려져 있고, 이는 전체 실행 시간 측면에서는 스플레이 트리가 좋은 자료구조라는 것을 의미합니다.
- $n$개의 원소가 있는 트리에 연산을 $m$번 수행할 때 전체 시간 복잡도는 $O((n+m) \log n)$
- Static optimality theorem: 원소가 삽입/삭제되지 않는 상황에서 모든 원소를 1번 이상 접근하는 경우, 다른 어떠한 BST보다 상수 배 이상 느리지 않음
- Scanning theorem: 모든 원소를 오름차순으로 한 번씩 splay 할 때 전체 시간 복잡도는 $O(n)$
- Queue theorem: $n$개의 원소가 있는 트리에 $m$번의
push_back,pop_front연산을 수행할 때 전체 시간 복잡도는 $O(n+m)$ - Deque conjecture: $n$개의 원소가 있는 트리에 $m$번의
push_front,push_back,pop_front,pop_back연산을 수행할 때 전체 시간 복잡도는 $O(n+m)$일 것이라는 추측 - Dynamic optimality conjecture: 트리에 여러 번 조작을 가했을 때 필요한 전체 연산의 횟수가 다른 어떠한 BST보다 상수 배 이상 많지 않을 것이라는 추측
하지만 여전히 연산 한 번의 시간 복잡도가 $O(n)$이 될 수 있다는 것은 서비스를 제공하는 입장에서 큰 문제입니다. 키보드를 한 번 눌렀더니 1초 정도의 딜레이가 발생하는 것이 긍정적인 경험을 주진 않을 것입니다. 스플레이 트리의 장점을 해치지 않으면서, 동시에 트리의 최대 높이를 적당한 수준으로 줄일 방법을 찾아야 합니다.
그 해결책은 예전에 알고리즘 문제를 풀던 경험에서 얻을 수 있었습니다. 연산의 시간 복잡도가 매번 $O(h^2)$인 BST 문제를 풀었던 적이 있는데, 이때 연산을 $X$번 수행할 때마다 정점을 임의로 $Y$개 선택해서 splay 하는 방식으로 나름의 rebalancing을 했던 기억이 있습니다. 마침 유저의 실제 사용 데이터(editing-trace.json, 삽입 182315회, 삭제 77463회)가 있어서, 이 데이터를 이용해 $X$와 $Y$를 바꿔가며 성능 변화를 관찰했습니다. 아래 표는 $X = \infty, Y=0$일 때의 최대 rotate 횟수와 전체 rotate 횟수를 각각 100% 라고 했을 때, $X, Y$ 값에 따른 rotate 횟수의 상대적인 차이를 나타내는 표입니다.
| X | Y | 최대 rotate 횟수 | 전체 rotate 횟수 |
|---|---|---|---|
| 100 | 1 | 30% | 130% |
| 100 | 5 | 15% | 223% |
| 100 | 10 | 11% | 333% |
| 500 | 1 | 34% | 107% |
| 500 | 5 | 36% | 127% |
| 500 | 10 | 26% | 150% |
| 1000 | 1 | 67% | 104% |
| 1000 | 5 | 35% | 115% |
| 1000 | 19 | 32% | 126% |
$X = 500, Y = 1$일 때 전체 rotate 연산 수행 횟수는 7% 밖에 상승하지 않으면서 최대 rotate 횟수는 66%를 감소시킬 수 있었습니다. 테스트 코드와 결과는 (여기)에서 확인할 수 있습니다.
현재 LLRBTree는 RGATreeSplit에서 분할할 지점의 인덱스가 주어지면 실제로 쪼개질 노드를 구할 때 사용하고 있으며, 모든 키가 정수라는 특징을 갖고 있습니다. SplayTree의 개선 방안을 모색할 때 키가 정수인 상황에서 사용할 수 있는 여러 자료구조를 공부했어서 이를 정리해 보고자 합니다. 아래 표에서 $n$은 원소 개수, $M$은 원소 범위 $[0, M=2^k)$를 의미합니다.
| rb tree | splay tree | y-fast trie | van Emde Boas tree | |
|---|---|---|---|---|
| search | $O(\log n)$ | amortized $O(\log n)$ | $O(\log \log M)$ | $O(\log \log M)$ |
| insert | $O(\log n)$ | amortized $O(\log n)$ | amortized $O(\log \log M)$ | $O(\log \log M)$ |
| delete | $O(\log n)$ | amortized $O(\log n)$ | amortized $O(\log \log M)$ | $O(\log \log M)$ |
| lower bound | $O(\log n)$ | amortized $O(\log n)$ | amortized $O(\log \log M)$ | $O(\log \log M)$ |
| space complexity | $O(n)$ | $O(n)$ | $O(n)$ | $O(M)$ or $O(n)$ with hashing |
복잡도 상으로는 y-fast trie나 van Emde Boas tree가 좋아 보이지만, 실제 수행 시간에서도 개선이 있을지는 확신이 서지 않아서 조사와 실험이 더 필요해 보입니다.
후기
이 밖에도 RHT의 여러 오류를 수정하기 위해 대부분의 기능을 처음부터 다시 구현하고 Tree.RemoveStyle 연산을 추가하는 작업(issue, PR1, PR2)도 했습니다. 이 작업을 하면서 살면서 처음으로 Go언어와 protobuf를 사용해 봤습니다.
프로그래밍 공부를 시작한 지 벌써 10년이 넘게 지났지만 아직 Git을 제대로 사용해 본 경험이 없고, 프로그래밍을 공부한 10년 중 7년이 넘는 시간을 알고리즘 공부에 투자했기 때문에 “개발”이라는 것을 많이 경험해 보지 못한 상태로 인턴십을 시작하게 되었습니다. 이번 인턴십을 통해 이런 문제를 해결해 보고 싶었고, 구체적으로 다음과 같은 3가지 목표를 세웠습니다.
- 이슈 생성 → 구조 설계 → 코드 작성 → PR 생성 → 코드 리뷰와 같은 개발 업무의 프로세스 익히기
- 지금까지 공부한 자료구조와 알고리즘을 실제 제품에 적용하기
- Git 사용과 문서 작업 등을 통해 다른 사람들과의 협업 경험해 보기
운 좋게도 저에게 맞는 프로젝트와 좋은 팀원들을 만나서 세 가지 목표 모두 잘 이룰 수 있었습니다.
PS를 했던 경험은 시간 복잡도를 계산하거나 자료구조를 직접적으로 다룰 때뿐만 아니라 회사에서 일하는 내내 은은하게 도움 되었습니다. 저는 제가 평소에 하는 일을 소개할 때 “문제를 풀고, 문제 푸는 방법을 가르치고, 문제를 만드는 사람”이라고 소개합니다. 세 가지 경험 모두 큰 도움이 되었습니다. 특히 코드를 작성하는 것과 동시에 예외 상황이나 반례를 떠올리는 것, 그리고 코드를 눈으로 디버깅하는 것은 PS를 하지 않았다면 거의 불가능했을 것 같습니다. 비슷한 맥락으로 사람들을 가르치고 코드를 디버깅해 준 것도 많은 도움이 되었습니다. 제가 생각했던 것보다도 남의 코드를 읽고 디버깅할 일이 매우 많았습니다. 문제를 출제하고 데이터를 만든 경험 덕분인지 “문제를 잘 정의하는 것과 테스트를 꼼꼼하게 작성하는 것에 큰 강점이 있다”라는 피드백을 듣기도 했습니다.
원래의 계획은 트리 동시 편집 테스트를 새로 작성한 다음 실제로 동시 편집 결과가 수렴하지 않는 케이스를 몇 개 해결하는 것이었습니다. 테스트 작성과 RHT의 동시 편집 지원까지는 잘 완성했지만, 트리 구조 문서의 동시 편집 문제를 하나도 해결하지 못한 채로 인턴 기간이 종료된 것이 많이 아쉬웠습니다. 이진 탐색 트리 부분도 더 개선해 보고 싶었는데, 충분히 고민하거나 실험할 시간이 없어서 이 부분도 거의 건들지 못했습니다. Yorkie는 오픈소스 프로젝트인 만큼 시간이 날 때마다 조금씩 더 기여해 보려고 합니다. 지금은 바빠서 추가로 작업을 하지 못하고 있지만 언젠가는 잘 끝낼 수 있을 때가 오길 바라며…
끝!